
AWS Lambdaはサーバーレスサービスの一つで、アプリケーションを実行するためのサーバー構築や管理をAWSに任せることができます。構築、管理をAWSに任せることで、利用者はプログラムの開発に集中することが可能になります。
サーバーレスとは何か、については以下の記事で解説しています。
https://envader.plus/article/60
この記事では、Lambda関数の中でも「レイヤー」について解説し、記事後半ではIaCツールのTerraformを使ってハンズオン形式でレイヤーの作成方法と利用方法を学びます。
レイヤーは、複数のLambda関数で共通して利用できるコードやライブラリを管理しやすくするための便利な機能なので、ぜひ手を動かしながら理解を深めていきましょう。
レイヤーとは
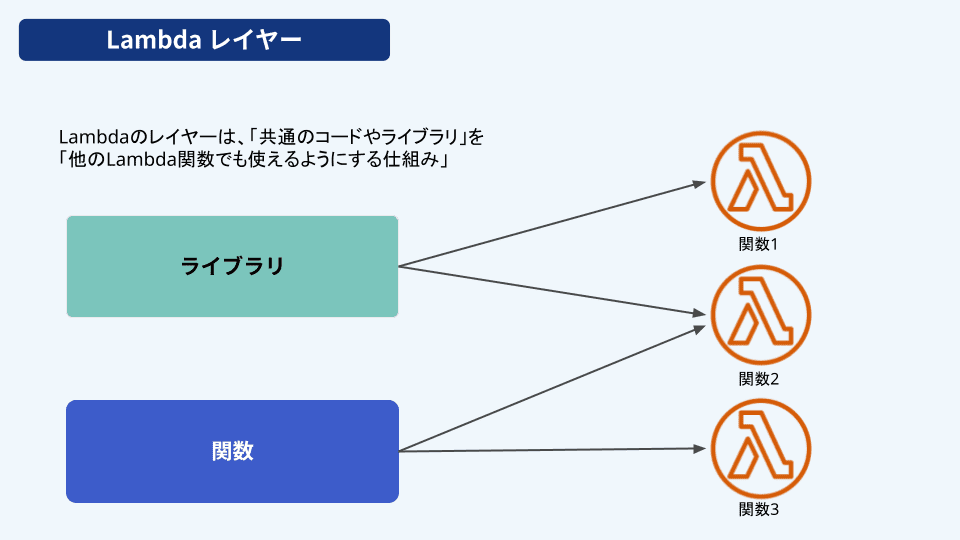
Lambdaのレイヤーは、「共通のコードやライブラリ」を「他のLambda関数でも使えるようにする仕組み」です。Lambda関数では依存するライブラリやモジュールを個別に関数に含めることが多いですが、レイヤーを使うとライブラリなどを1か所にまとめて管理できるようになります。
そのため、複数のLambda関数で同じライブラリやモジュールを使う場合に、個別に管理する手間を省くことができます。例えば、Node.jsでよく利用するExpressやAxiosといったライブラリを、関数Aと関数Bがどちらも使用する場合、ライブラリをレイヤーとして管理することでどちらの関数でもライブラリを利用できるようになります。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/chapter-layers.html
レイヤーを使うメリット
ここからは、レイヤーを使うメリットについて見ていきます。
同じコード、ライブラリを複数の関数で使える
先述しましたが、レイヤーを使うことで複数のLambda関数で共通のコードやライブラリを効率的に共有できます。たとえば、よく使われる処理やライブラリをレイヤーにまとめておけば、1つのレイヤーを複数の関数で再利用することができます。
こうすることで、同じライブラリやコードを毎回個別の関数に書く必要がなくなり、コードの重複を減らせます。
デプロイパッケージのサイズを小さくできる
関数のコードとライブラリを別々にすることで、デプロイパッケージのサイズを小さくできます。
Lambda関数にコードとライブラリを含めてしまうと、場合によってはパッケージのサイズが大きくなってしまいます。
パッケージのサイズが大きくなることで、AWSへのデプロイ時間の増加、Lambdaのデプロイサイズ制限(ZIP圧縮時で最大50MB)に引っかかってしまうなどの影響が考えられます。
レイヤーを利用することでコードとライブラリの部分を分割できるため、デプロイ時間の短縮や、デプロイサイズの制限を超えないようにすることが可能になります。
Lambdaコンソールのコードエディタが使える
レイヤーを使うことでデプロイパッケージのサイズを小さくできるため、コードエディタが使えます。
パッケージのサイズが大きいと、Lambdaコンソールのコードエディタでコードを直接編集できなくなってしまいます。こうなると、小さな修正や調整を行いたい場合でもローカル環境でコードを編集し、デプロイし直す手間がかかってしまいます。
レイヤーを使用しデプロイパッケージサイズを小さくすれば、Lambdaコンソールのコードエディタで編集できるため、修正や調整などにかける時間を短縮することが可能になります。
レイヤー利用時の注意点
ここまででレイヤーのメリットについて解説しました。ここからは、実際にレイヤーを利用する際に注意すべき点を解説します。
レイヤーサイズの制限
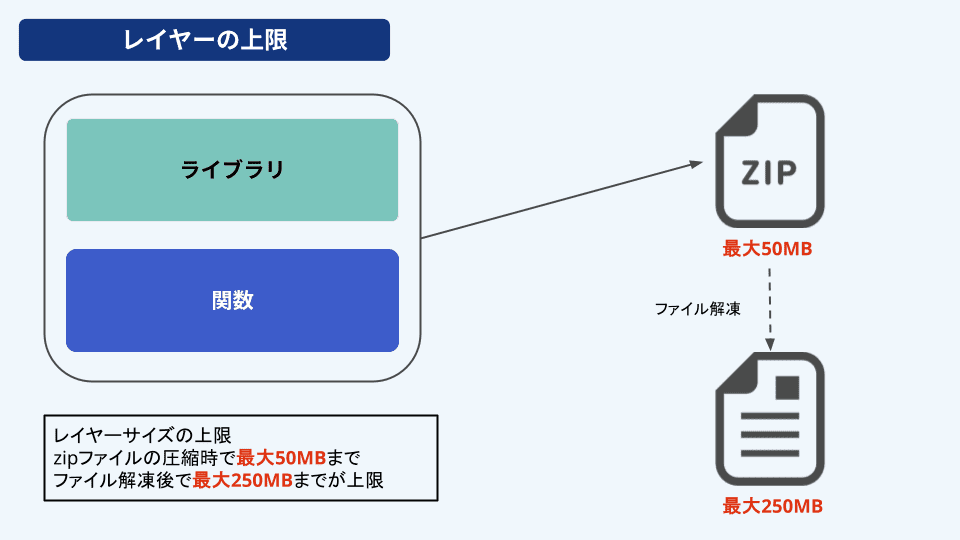
デプロイパッケージ同様、レイヤーにもサイズの制限があります。それぞれのレイヤーサイズはzipファイルの圧縮時で最大50MB、ファイル解凍後で最大250MBという制限があり、制限を超えてしまうとレイヤーをデプロイすることができません。
レイヤーに多くのライブラリなどを含めてしまうとこの上限を超えてしまうため、レイヤー化する場合は必要最小限のレイヤー構成にする必要があります。
レイヤーのアップデート
レイヤーに含まれるコードやライブラリをアップデートした場合、関数には自動的に反映されないため注意が必要です。
レイヤーの内容をアップデートした場合には、新しくバージョンを作成することになります。そのため、レイヤーアップデート後に、関数側で明示的にそのレイヤーのバージョンを指定する必要があります。
レイヤーのアップデート後、関数側でレイヤーバージョンの更新をしなかった場合、古いレイヤーのバージョンを使い続けることになってしまうため、レイヤーを更新した時には関数でレイヤーバージョンを指定することが必要です。
レイヤーのディレクトリ構造
各ランタイムのライブラリをレイヤーに含める場合、特定のフォルダ構造にする必要があります。例としてNode.jsのライブラリをLambdaが正しく読み込むには、レイヤーの中に次のようなディレクトリ構造が必要です。
nodejs/node_modules/たとえば、Expressというライブラリをレイヤーに追加する場合、ローカルにnodejs フォルダを作成し、その中のnode_modulesフォルダにライブラリのインストールが必要です。
インストール後、nodejsフォルダ全体をzipファイル化しレイヤーを作成することで、Lambda関数は/opt/nodejs/node_modulesを参照し、レイヤーを認識します。
それぞれのランタイムによってこのディレクトリ構造は異なるため、ドキュメントに沿った実装が必要になります。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/packaging-layers.html#packaging-layers-paths
Terraformでレイヤーを作成してみよう
このセクションでは、Terraformを使ってLambda関数のレイヤーを作成する方法を解説します。
Terraformを使用するには、Terraformのインストールや設定が必要になります。まだ設定が済んでいない場合は、次の記事を参考に環境を構築しましょう。
https://envader.plus/article/162
Node.jsランタイムを使用し、Lambdaレイヤーを作成して他のLambda関数で共通のコードを利用できるようにします。
ディレクトリ構成
今回実施するハンズオンのディレクトリ構成は次のようになります。
layer-functionsのディレクトリ構成が重要になってくるため、良く確認して作成しましよう。
.
├── lambda-functions
│ └── index.mjs
├── layer-functions
│ └── nodejs
│ └── node_modules
│ └── utils.mjs
├── main.tf
└── versions.tflambda-functionsディレクトリには、Lambda関数のコードが入っています。utils.mjsファイルからformatString関数をインポートして利用します。
layer-functionsディレクトリは、レイヤーに含める共通で利用するコードを格納するディレクトリになります。注意点のところで解説したように、nodejs/node_modules/の構成にする必要があるため注意が必要です。
筆者はここでハマりましたが、この構成にしないとLambda関数で読み込むことができずエラーになるため、ディレクトリ構成には注意しましょう。
index.mjs
Lambda関数で使用するメインの関数です。ここでレイヤーとして作成したutils.mjsをインポートして利用します。
今回は単純に文字列を出力する関数になります。
// index.mjs
import { formatString } from '/opt/nodejs/node_modules/utils.mjs';
export const handler = async (event) => {
const formatted = formatString("hello from lambda!");
return {
statusCode: 200,
body: JSON.stringify({ message: formatted }),
};
};utils.mjs
レイヤーに追加する共通コードです。このファイルはformatStringという関数を定義し、渡された文字列を大文字に変換します。
index.mjsでこの関数をインポートし、文字列を大文字に変換して出力します。
// utils.mjs
export function formatString(str) {
return str.toUpperCase();
}main.tf
main.tfで、LambdaレイヤーとLambda関数をTerraformで作成するための設定を記述します。
# main.tf
# ZIPアーカイブを作成 (レイヤー用)
data "archive_file" "layer_zip" {
type = "zip"
source_dir = "${path.module}/layer-functions" # node_modulesが含まれているディレクトリへのパス
output_path = "${path.module}/utils-layer.zip"
}
# Lambdaレイヤーの作成
resource "aws_lambda_layer_version" "utils_layer" {
layer_name = "UtilsFunctionLayer"
filename = data.archive_file.layer_zip.output_path
compatible_runtimes = ["nodejs20.x"]
source_code_hash = data.archive_file.layer_zip.output_base64sha256
}
# ZIPアーカイブを作成 (Lambda関数用)
data "archive_file" "lambda_function_zip" {
type = "zip"
source_dir = "${path.module}/lambda-functions" # Lambda関数コードが含まれているディレクトリへのパス
output_path = "${path.module}/lambda-function.zip"
}
# Lambda関数の作成
resource "aws_lambda_function" "dev_lambda_function" {
function_name = "dev-lambda-function"
role = aws_iam_role.lambda_exec.arn
handler = "index.handler"
runtime = "nodejs20.x"
filename = data.archive_file.lambda_function_zip.output_path
source_code_hash = data.archive_file.lambda_function_zip.output_base64sha256
# レイヤーをLambda関数に追加
layers = [
aws_lambda_layer_version.utils_layer.arn
]
}
# IAMロールの作成
resource "aws_iam_role" "lambda_exec" {
name = "lambda_exec_role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
# IAMポリシーのアタッチ
resource "aws_iam_role_policy_attachment" "lambda_policy" {
role = aws_iam_role.lambda_exec.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}Lambdaのレイヤーは、以下のコードで作成しています。
# ZIPアーカイブを作成 (レイヤー用)
data "archive_file" "layer_zip" {
type = "zip"
source_dir = "${path.module}/layer-functions" # node_modulesが含まれているディレクトリへのパス
output_path = "${path.module}/utils-layer.zip"
}
# Lambdaレイヤーの作成
resource "aws_lambda_layer_version" "utils_layer" {
layer_name = "UtilsFunctionLayer"
filename = data.archive_file.layer_zip.output_path
compatible_runtimes = ["nodejs20.x"]
source_code_hash = data.archive_file.layer_zip.output_base64sha256
}data "archive_file"でzipファイル化するディレクトリを指定します。特に注意が必要なのが、source_dirで指定するディレクトリです。
先述したように、Lambda関数のレイヤーは特定のディレクトリ構造にしなければいけません。Node.jsではnodejs/node_modules/を含めるようにする必要があります。
"${path.module}/layer-functions"とすることで、layer-functions以下のディレクトリをzipファイル化することができます。
例えば、"${path.module}/layer-functions"/nodejsで指定すると、zipファイルにはnode_modules/からの内容のみが含まれてしまい、Lambda関数実行時にエラーになってしまいます。
筆者はここでハマってしまったため、リソースを作成する際は注意しましょう。
そのほかのコードの読み方に関しては、以下ハンズオン記事で解説しています。
https://envader.plus/article/466
https://envader.plus/article/467
versions.tf
今回のLambdaでは、ランタイムにNodejs20.xを指定します。TerraformでNodejs20.xを使用するには、プロバイダーバージョンを5.26.0以上にする必要があります。
https://github.com/hashicorp/terraform-provider-aws/pull/34401#issuecomment-1815494193
# versions.tf
terraform {
required_version = ">= 1.0.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.26.0"
}
}
}
provider "aws" {
region = "ap-northeast-1"
}テストの実行
コード作成後、plan結果を確認しapplyを実行。Lambda関数とレイヤーをデプロイします。
terraform plan
terraform applyLambda関数をデプロイ後、AWS CLIでテストを実行します。
--payloadでは関数に渡す値を指定しますが、今回は文字列を表示させるだけのため指定しません。
テストの実行結果をoutput.jsonに保存します。
aws lambda invoke --function-name <関数名> --payload '{}' output.jsonテストを実行後、作成されたoutput.jsonの内容を確認します。文字列が大文字に変換されていることがわかります。
cat output.json
{"statusCode":200,"body":"{\"message\":\"HELLO FROM LAMBDA!\"}"}まとめ
この記事では、AWS Lambdaのレイヤー機能について解説し、Terraformを使って実際にレイヤーを作成しました。レイヤーを使うことで、複数のLambda関数で共通のコードやライブラリを共有し、コードの重複排除やデプロイパッケージのサイズを削減するメリットを得られます。
また、レイヤー利用時の注意点やTerraformによる実装方法についても詳しく紹介しました。特に、レイヤーのディレクトリ構造やファイル指定の際にミスしやすい点についても触れましたので、実際の実装時に役立ててください。
手を動かしながら、理解を深めていっていただければ幸いです。
参考記事
【実践】TerraformのinstallからAWS EC2の作成〜ssh接続までを実践してみた
【Terraformハンズオン】同期呼び出しのLambda関数をデプロイしてみよう
【番外編】USBも知らなかった私が独学でプログラミングを勉強してGAFAに入社するまでの話

プログラミング塾に半年通えば、一人前になれると思っているあなた。それ、勘違いですよ。「なぜ間違いなの?」「正しい勉強法とは何なの?」ITを学び始める全ての人に知って欲しい。そう思って書きました。是非読んでみてください。
「フリーランスエンジニア」
近年やっと世間に浸透した言葉だ。ひと昔まえ、終身雇用は当たり前で、大企業に就職することは一種のステータスだった。しかし、そんな時代も終わり「優秀な人材は転職する」ことが当たり前の時代となる。フリーランスエンジニアに高価値が付く現在、ネットを見ると「未経験でも年収400万以上」などと書いてある。これに釣られて、多くの人がフリーランスになろうとITの世界に入ってきている。私もその中の1人だ。数年前、USBも知らない状態からITの世界に没入し、そこから約2年間、毎日勉学を行なった。他人の何十倍も努力した。そして、企業研修やIT塾で数多くの受講生の指導経験も得た。そこで私は、伸びるエンジニアとそうでないエンジニアをたくさん見てきた。そして、稼げるエンジニア、稼げないエンジニアを見てきた。
「成功する人とそうでない人の違いは何か?」
私が出した答えは、「量産型エンジニアか否か」である。今のエンジニア市場には、量産型エンジニアが溢れている!!ここでの量産型エンジニアの定義は以下の通りである。
比較的簡単に学習可能なWebフレームワーク(WordPress, Rails)やPython等の知識はあるが、ITの基本概念を理解していないため、単調な作業しかこなすことができないエンジニアのこと。
多くの人がフリーランスエンジニアを目指す時代に中途半端な知識や技術力でこの世界に飛び込むと返って過酷な労働条件で働くことになる。そこで、エンジニアを目指すあなたがどう学習していくべきかを私の経験を交えて書こうと思った。続きはこちらから、、、、

エンベーダー編集部
エンベーダーは、ITスクールRareTECHのインフラ学習教材として誕生しました。 「遊びながらインフラエンジニアへ」をコンセプトに、インフラへの学習ハードルを下げるツールとして運営されています。


関連記事
2024.10.19
【Terraformハンズオン】Terraformでモジュールを作成してみよう
この記事では、Terraformのモジュールに焦点を当て、記事前半で基本を解説し、後半でEC2、VPCモジュールを作成するハンズオンを行います。
- AWS
- Terraform
- ハンズオン

2026.03.12
Terraform組み込み関数の使い方|よく使う関数の構文と使用例まとめ
Terraformの組み込み関数とは、値の変換や操作を行うために標準で用意された関数です。format・join・lookup・elementなど、よく使う関数の構文と使用例をカテゴリ別に解説します。
- インフラエンジニア
- AWS
- Terraform

2024.06.23
【Terraformハンズオン】AWS SNSの基本とメール通知を実践してみよう
こちらの記事では、Amazon SNSの基本を解説し、Terraformを使ったハンズオンを行います。
- AWS
- ハンズオン
2024.02.27
AWS ALBとAzure Application Gatewayの違い
この記事では、クラウドコンピューティングの二大巨頭、Amazon Web Services (AWS) の Application Load Balancer (ALB) と Microsoft Azure の Application Gateway (アプリケーションゲートウェイ)の間で、Web アプリケーション向けのロードバランサーサービスを比較します。
- AWS
- Azure