AWS LambdaはAWSが提供するサーバーレスなサービスで、Lambdaを使用することで開発者はサーバーの管理を気にすることなくコードの実行を行えます。
Lambda関数の実行には大きく分けて「同期呼び出し」と「非同期呼び出し」「イベントソースマッピング」の3つが存在します。それぞれ、関数を呼び出した後の処理に違いがあり、利用目的に沿って使い分けることが重要になります。
こちらの記事では、Lambda関数の「非同期呼び出し」に焦点を絞って解説し、Terraformを使ったハンズオンを行います。
AWSを管理するインフラエンジニアには、Lambda関数の理解は必要不可欠になりますので、読むだけでなく、実際に手を動かしながら「非同期呼び出し」とは何なのかを理解していきましょう。
非同期呼び出しのLambda関数
非同期呼び出しのLambda関数は、呼び出し元(クライアント)が関数の実行完了を待たずに次の処理に進むことができる呼び出し方法です。非同期呼び出しでは、Lambdaが裏で動いている間にクライアントは他の作業を続けることができます。
非同期呼び出しは、ユーザーがアップロードした画像のリサイズ処理や大量データのバッチ処理、メール送信処理など、バックグラウンドで実行したい処理に適しています。
非同期呼び出しのメリット
非同期呼び出しのメリットを考えてみます。
ユーザーが注文した際に、注文完了メールを送信する処理を考えてみましょう。
同期呼び出しではメール送信が完了するまでユーザーは待たされ、システムの処理が完了するのを待つ必要があります。
非同期呼び出しであればメール送信処理は裏側で行われ、ユーザーは注文が完了した時点で次の操作へ進めるようになります。
このように非同期呼び出しの大きなメリットは、関数が実行されている間もユーザーに影響を与えない点です。関数が動いている間でもユーザーは他の作業を進めることができるため、システム全体の効率を上げることができます。
同期呼び出しとは
もう一つの呼び出し方法、同期呼び出しに関しても簡単に解説します。
同期呼び出しでは、クライアントが直接Lambda関数を呼び出し、レスポンスを受け取るまで待ち続けます。そのため、関数の処理が完了するまでクライアントは次の作業に進めません。関数の処理が終わり、完了のレスポンスを受け取ってから次の作業に進みます。
同期呼び出しは、クライアントがボタンをクリック後にレスポンスを返したい時や、リアルタイムにデータを計算してその場で表示する必要がある場合など、すぐにレスポンスが必要が処理に適しています。
非同期呼び出しのLambda関数の特徴
ここからは、非同期呼び出しのLambda関数の仕組みを詳しく見ていきます。
イベントキューと並列処理
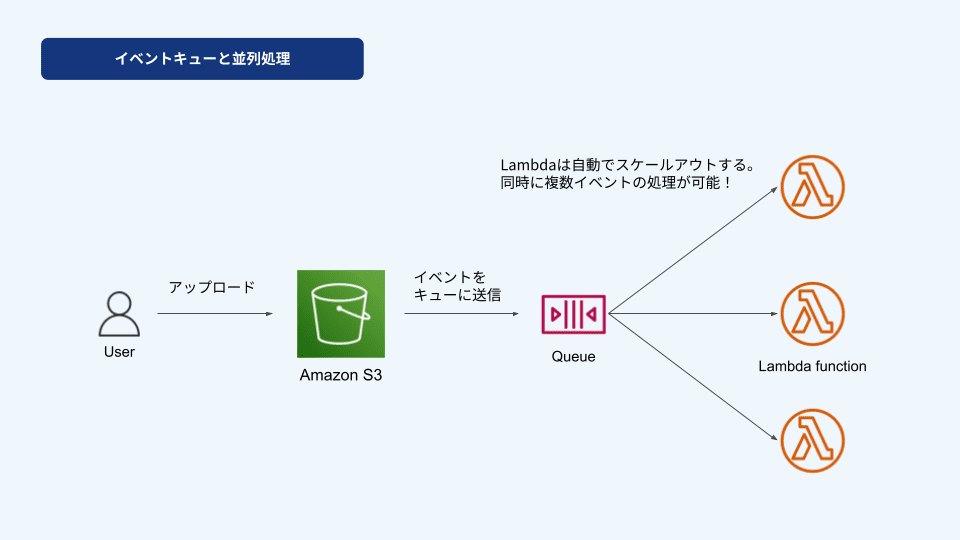
非同期呼び出しのLambdaでは、関数が呼び出されるとイベント(処理のリクエスト)をキューに一時的に保存します。キューに入れられたイベントは順番に処理されるため、クライアントは関数の実行が終わるのを待たずにすぐにレスポンスを受け取ることができます。
簡単に言うと、「今すぐやらなくてもいいけど、後でやっておいてね」というタスクをまとめてリストにして、後から順番にこなしていくイメージです。
さらに、Lambdaは自動でスケールアウトするため、同時に複数のイベントを処理することができます。そのためキューにたくさんのイベントがあっても並列に処理を進められ、効率的にタスクをこなすことが可能になります。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/invocation-async.html
再試行の仕組み

Lambdaの非同期呼び出しでは、万が一エラーが発生した時には自動でリトライ処理が行われます。
このリトライ処理はデフォルトで2回実行され、それでもエラーが解消されない場合、このイベントは処理されずに終了します。
リトライ処理には待機時間があり、1回目のエラー発生時には1分間、その後のリトライ処理には2分間の待機時間があります。
このリトライ処理があることで、ネットワーク障害や一時的なシステムの不具合など、比較的短時間で解消される可能性がある問題に対して自動で対応することができます。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/invocation-async-error-handling.html
デッドレターキュー (DLQ)

Lambdaの非同期呼び出しでは、リトライ処理が2回行われてもエラーが解消されない場合、そのイベントは処理されずに終了します。ただ、この失敗したイベントをデッドレターキュー(DLQ)に送信することで、エラー発生後の対処が可能になります。
DLQは失敗したイベントを記録するための場所になり、この記録を残しておくことでエラーの原因を追及したり、エラー発生時に早く気づいて対応できるメリットがあります。
DLQはAmazon SQS、Amazon SNSと連携することが可能で、利用する場合には別途設定が必要になります。
また、DLQを設定する際はLambdaのIAM PolicyにSQSやSNSに対する権限を追加する必要があります。設定する際はこちらも理解しておき、適切に権限を設定するよう注意が必要です。
Terraformで非同期呼び出しのLambda関数をデプロイする
ここからはIaCツールのTerraformを使って、実際に非同期呼び出しのLambda関数を作成します。
今回のハンズオンでは、Amazon S3をトリガーにしたLambda関数を作成します。
Amazon S3に関しては以下の記事で解説しているためぜひ参照ください。
https://envader.plus/article/46
ディレクトリの作成
はじめに作業用のディレクトリを作成し、その中で作業を行います。
mkdir lambda-async
cd lambda-async最終的なディレクトリ構成は以下となります。
.
├── lambda-functions
│ └── lambda_function.py
├── main.tf
├── sample.txt
├── terraform.tfstate
└── versions.tfプロバイダーの設定
versions.tf ファイルを作成し、以下の内容を記述します。
terraform {
required_version = ">= 1.0.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.0.0"
}
}
}
provider "aws" {
region = "ap-northeast-1"
}main.tf
main.tfのソースコード全体は以下になります。
# Lambda関数用のIAM Role
resource "aws_iam_role" "lambda_role" {
name = "lambda_execution_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Action = "sts:AssumeRole",
Effect = "Allow",
Principal = {
Service = "lambda.amazonaws.com"
}
}]
})
}
# LambdaがCloudWatch Logsにアクセスするためのポリシーをアタッチ
resource "aws_iam_role_policy_attachment" "lambda_basic_execution" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
# LambdaがS3にアクセスするためのポリシーを作成
resource "aws_iam_policy" "lambda_s3_policy" {
name = "lambda_s3_access_policy"
description = "Lambda S3 access policy"
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Action = [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
Effect = "Allow",
Resource = [
"arn:aws:s3:::hands-on-bucket-2024",
"arn:aws:s3:::hands-on-bucket-2024/*"
]
}
]
})
}
# 作成したIAM PolicyをIAM Roleへアタッチ
resource "aws_iam_role_policy_attachment" "lambda_s3_policy_attachment" {
role = aws_iam_role.lambda_role.name
policy_arn = aws_iam_policy.lambda_s3_policy.arn
}
# S3バケットの作成
resource "aws_s3_bucket" "hands_on_bucket" {
bucket = "hands-on-bucket-2024"
}
# S3バケットのオブジェクト作成イベントでLambda関数を呼び出す通知設定
resource "aws_s3_bucket_notification" "bucket_notification" {
bucket = aws_s3_bucket.hands_on_bucket.bucket
lambda_function {
lambda_function_arn = aws_lambda_function.s3_move_lambda.arn
events = ["s3:ObjectCreated:*"] # オブジェクトが作成された際にイベントを発生させる
}
depends_on = [aws_lambda_permission.allow_s3_invocation] # Lambda関数がS3からの呼び出しを許可される必要がある
}
# Lambda関数の定義
resource "aws_lambda_function" "s3_move_lambda" {
function_name = "s3_move_lambda_function"
role = aws_iam_role.lambda_role.arn
handler = "lambda_function.lambda_handler"
runtime = "python3.9"
filename = data.archive_file.main.output_path
source_code_hash = data.archive_file.main.output_base64sha256
}
# Lambda関数のzip化
data "archive_file" "main" {
type = "zip"
source_dir = "${path.module}/lambda-functions"
output_path = "${path.module}/lambda-functions.zip"
}
# S3バケットからLambda関数を呼び出すための権限を付与
resource "aws_lambda_permission" "allow_s3_invocation" {
statement_id = "AllowExecutionFromS3" # この権限設定に対する識別ID
action = "lambda:InvokeFunction" # Lambda関数を呼び出すアクションを許可
function_name = aws_lambda_function.s3_move_lambda.function_name # 権限を付与するLambda関数
principal = "s3.amazonaws.com" # 呼び出し元はS3サービス
source_arn = aws_s3_bucket.hands_on_bucket.arn # このS3バケットからの呼び出しに限定
}Lambda関数の定義、archiveファイルの作成に関しては、以下リンクの記事で解説していますので、ご参照ください。
https://envader.plus/article/466
S3バケットのイベント通知設定
S3バケットにオブジェクトが作成されたときに、Lambda関数がトリガーされるよう設定します。
# S3バケットのオブジェクト作成イベントでLambda関数を呼び出す通知設定
resource "aws_s3_bucket_notification" "bucket_notification" {
bucket = aws_s3_bucket.hands_on_bucket.bucket
lambda_function {
lambda_function_arn = aws_lambda_function.s3_move_lambda.arn
events = ["s3:ObjectCreated:*"] # オブジェクトが作成された際にイベントを発生させる
}
depends_on = [aws_lambda_permission.allow_s3_invocation] # Lambda関数がS3からの呼び出しを許可される必要がある
}Lambda関数にS3からの実行許可を付与
S3がLambda関数を呼び出せるように実行権限を設定します。
# S3バケットからLambda関数を呼び出すための権限を付与
resource "aws_lambda_permission" "allow_s3_invocation" {
statement_id = "AllowExecutionFromS3" # この権限設定に対する識別ID
action = "lambda:InvokeFunction" # Lambda関数を呼び出すアクションを許可
function_name = aws_lambda_function.s3_move_lambda.function_name # 権限を付与するLambda関数
principal = "s3.amazonaws.com" # 呼び出し元はS3サービス
source_arn = aws_s3_bucket.hands_on_bucket.arn # このS3バケットからの呼び出しに限定
}Lambda関数のコードを作成
main.tfファイル作成後、lambda-functionsディレクトリを作成します。
mkdir lambda-functionslambda_function.py ファイルを作成後、ソースコードを記述します。
touch lambda-function.pyソースコード
# lambda-function.py
import json
import boto3
import urllib.parse
s3 = boto3.client('s3')
def lambda_handler(event, context):
# イベントからバケット名とオブジェクトキーを取得
source_bucket = event['Records'][0]['s3']['bucket']['name']
source_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
# 目的のプレフィックス(移動先のパス)を設定
destination_prefix = 'processed/'
destination_key = destination_prefix + source_key.split('/')[-1]
try:
# オブジェクトをコピー
copy_source = {
'Bucket': source_bucket,
'Key': source_key
}
s3.copy_object(
CopySource=copy_source,
Bucket=source_bucket,
Key=destination_key
)
print(f"Copied {source_key} to {destination_key}")
# 元のオブジェクトを削除
s3.delete_object(Bucket=source_bucket, Key=source_key)
print(f"Deleted original object {source_key}")
except Exception as e:
print(f"Error processing object {source_key} from bucket {source_bucket}.")
print(e)
raise eこのコードでは、アップロードされたオブジェクト(ファイル)のバケット名とキー(パス)を取得後、コピー先のキーを設定し、同じバケット内の別のプレフィックス(ここでは processed/)にオブジェクトを移動します。
s3.copy_object を使用してオブジェクトをコピーし、s3.delete_objectで元のオブジェクトを削除します。
Terraformの実行
すべての設定が完了したら、Terraformを実行してリソースをデプロイします。
terraform init
terraform applyterraform apply を実行すると、作成されるリソースの詳細が表示されます。内容を確認して yes と入力してください。
S3へファイルをアップロード
S3バケットにファイルをアップロードして、オブジェクトが指定した場所に移動されることを確認します。
# 任意のファイルを作成
echo "Sample content" > sample.txt
# ファイルをアップロード
aws s3 cp sample.txt s3://hands-on-bucket-2024/sample.txt は任意のファイルで作成し、内容をリダイレクトして書き込みます。
作成したファイルをアップロードするとLambda関数が非同期でトリガーされ、ファイルは processed/ プレフィックスに移動されます。
以下コマンドでファイルをコピーします。
aws s3 cp sample.txt s3://your-unique-bucket-name-1234567890/コピー完了後、processed/にファイルが移動されているかを確認します。
aws s3 ls s3://hands-on-bucket-2024/processed/
2024-xx-xx xx:04:10 15 sample.txtprocessed/配下にsample.txtがあることを確認できればLambdaの実行完了です。
CloudWatch Logsでログを確認
Lambda関数の実行ログはCloudWatch Logsに出力されます。AWS CLIで以下コマンドを実行し、ログを確認します。
# コマンド例
aws logs tail "CloudWatchロググループ名" --follow
aws logs tail "/aws/lambda/s3_move_lambda_function" --followコピーと削除を実行したログが含まれていることが確認できます。
xxxx-xx-xxT20:57:19.677000+00:00 xxxx/xx/xx/[$LATEST]8e538664904a4a9285424e4110deecfc INIT_START Runtime Version: python:3.9.v56 Runtime Version ARN: arn:aws:lambda:ap-northeast-1::runtime:52e9b67213e4ba48e3c265ce3aa86c478ce792bbd68bc88225db1202a975ddda
xxxx-xx-xxT20:57:20.096000+00:00 xxxx/xx/xx/[$LATEST]8e538664904a4a9285424e4110deecfc START RequestId: 91b754e9-8c11-4968-93a9-3a1a5ebe9507 Version: $LATEST
xxxx-xx-xxT20:57:20.421000+00:00 xxxx/xx/xx/[$LATEST]8e538664904a4a9285424e4110deecfc Copied sample.txt to processed/sample.txt
xxxx-xx-xxT20:57:20.461000+00:00 xxxx/xx/xx/[$LATEST]8e538664904a4a9285424e4110deecfc Deleted original object sample.txt
xxxx-xx-xxT20:57:20.481000+00:00 xxxx/xx/xx/[$LATEST]8e538664904a4a9285424e4110deecfc END RequestId: 91b754e9-8c11-4968-93a9-3a1a5ebe9507まとめ
今回の記事では、非同期呼び出しのLambda関数の基本的な仕組みや特徴を解説しました。
また、Terraformを使って実際にLambda関数をデプロイするハンズオンを解説しました。
非同期呼び出しのメリットとして、クライアントが処理を待たずに次の作業へ進める点が挙げられ、システム全体の効率を高めることができます。
ハンズオンでは、Amazon S3をトリガーにLambda関数を非同期で実行し、S3内のファイルを別のプレフィックスに移動するシンプルな例を通じて、非同期処理の動作を確認しました。
今回のハンズオンが、皆様の理解の一歩になれば幸いです。
参考資料
【番外編】USBも知らなかった私が独学でプログラミングを勉強してGAFAに入社するまでの話

プログラミング塾に半年通えば、一人前になれると思っているあなた。それ、勘違いですよ。「なぜ間違いなの?」「正しい勉強法とは何なの?」ITを学び始める全ての人に知って欲しい。そう思って書きました。是非読んでみてください。
「フリーランスエンジニア」
近年やっと世間に浸透した言葉だ。ひと昔まえ、終身雇用は当たり前で、大企業に就職することは一種のステータスだった。しかし、そんな時代も終わり「優秀な人材は転職する」ことが当たり前の時代となる。フリーランスエンジニアに高価値が付く現在、ネットを見ると「未経験でも年収400万以上」などと書いてある。これに釣られて、多くの人がフリーランスになろうとITの世界に入ってきている。私もその中の1人だ。数年前、USBも知らない状態からITの世界に没入し、そこから約2年間、毎日勉学を行なった。他人の何十倍も努力した。そして、企業研修やIT塾で数多くの受講生の指導経験も得た。そこで私は、伸びるエンジニアとそうでないエンジニアをたくさん見てきた。そして、稼げるエンジニア、稼げないエンジニアを見てきた。
「成功する人とそうでない人の違いは何か?」
私が出した答えは、「量産型エンジニアか否か」である。今のエンジニア市場には、量産型エンジニアが溢れている!!ここでの量産型エンジニアの定義は以下の通りである。
比較的簡単に学習可能なWebフレームワーク(WordPress, Rails)やPython等の知識はあるが、ITの基本概念を理解していないため、単調な作業しかこなすことができないエンジニアのこと。
多くの人がフリーランスエンジニアを目指す時代に中途半端な知識や技術力でこの世界に飛び込むと返って過酷な労働条件で働くことになる。そこで、エンジニアを目指すあなたがどう学習していくべきかを私の経験を交えて書こうと思った。続きはこちらから、、、、

エンベーダー編集部
エンベーダーは、ITスクールRareTECHのインフラ学習教材として誕生しました。 「遊びながらインフラエンジニアへ」をコンセプトに、インフラへの学習ハードルを下げるツールとして運営されています。


関連記事

2025.05.06
初心者でもサクッとDockerでアプリをデプロイする方法
この記事では、初心者でもDockerを使って簡単なWebアプリケーションをデプロイし、実際に動かせるように、基本的な流れを丁寧に解説します。さらに、アプリケーションの更新や削除方法も説明するので、Dockerを使いこなせるようになるはずです。
- Docker
- ハンズオン
2024.06.19
サーバーレス初心者必見!AWS Lambda関数URLの設定と実践方法
この記事では、AWS初心者向けにLambda関数URLの設定と利用方法について解説します。
- AWS

2024.10.28
AWS CloudFormationでインフラをコード化する!初心者向けテンプレート作成ガイド
CloudFormationを利用するメリットには、インフラのスケーラビリティを向上させること、プロジェクトの展開速度を上げること、そしてリソースの再利用を容易にすることが含まれます。結果として、運用の効率化が図れます。
- AWS
- AWS

2024.04.14
DockerにGoでREST APIのTODOアプリを作るとDockerと仲良くなれる
今回は、「Dockerを使ってみたいけどよくわからない」という人を対象に、Docker上にGoを使ってREST APIで操作するTODOアプリケーションを作成することで、Dockerの操作に慣れていきましょう。
- ハンズオン
- Docker
- go