
はじめに
AWSのAmazon EC2 Auto Scalingは、アプリケーションの負荷に応じてAmazon EC2インスタンスの数を自動で調整するサービスです。このサービスを利用することで、アプリケーションの需要が増加した場合には自動的にスケールアウト(インスタンスの追加)を行い、需要が減少した場合にはスケールイン(インスタンスの削減)を行います。Amazon EC2 Auto Scalingを利用することで、ユーザーが手動で操作を行わなくても最適なパフォーマンスを維持しつつ、コストを効率的に管理することができます。
こちらの記事では、Amazon EC2 Auto Scalingの機能をTerraformで実装する方法を解説します。
Terraformを利用するには環境構築が必要になります。installや基本的な設定は以下の記事で解説しています。
https://envader.plus/article/162
Terraformを使用することで、インフラストラクチャをコードとして定義し、コードを通じてインフラストラクチャの作成、変更、管理ができるようになります。是非手を動かしながら、Amazon EC2 Auto Scalingの実装方法を理解しましょう。
Amazon EC2 Auto Scalingとは
Amazon EC2 Auto Scalingは、EC2のみを対象にAuto Scalingを実現させるAWSのサービスです。
AWSのAuto Scalingは3種類あり、EC2のみを対象にした「EC2 Auto Scaling」、ECSやLambda、Dynamo DBなど色々なAWSサービスを対象にした「Application Auto Scaling」、現在「新規適用は非推奨」とされていますが、2つのサービスをまとめて管理することができる「AWS Auto Scaling」の3つがあります。
今回の記事では、この3つの内「EC2 Auto Scaling」に焦点を当てて解説していきます。
Auto Scalingとは?
はじめに、Auto Scalingとは何なのか?について解説します。
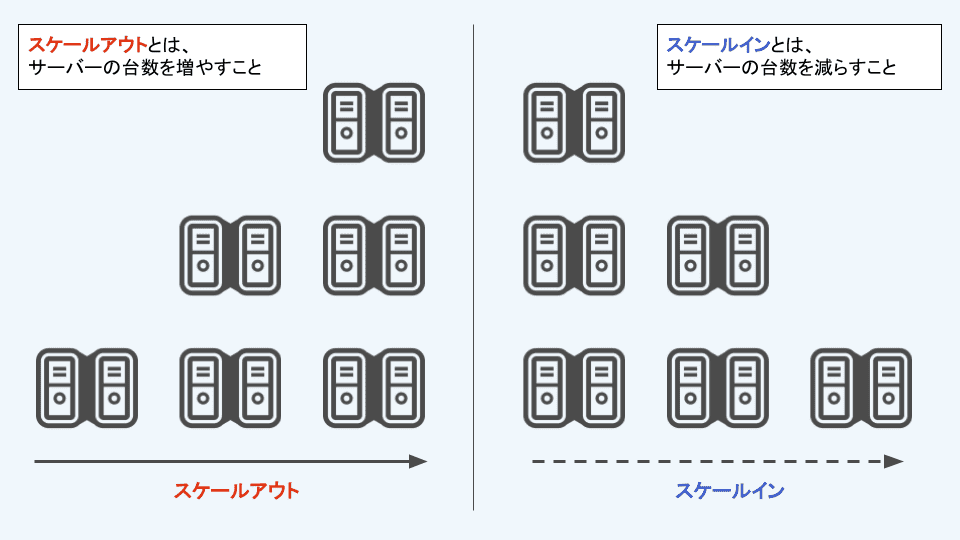
Auto Scalingとは、アプリケーションの需要に合わせてサーバーの数を自動的に増減させるシステムのことです。

例えば、オンラインショップが1台でサーバーを運用していた場合、セール期間中にアクセスが急増するとサーバーに対する負荷が上がり、大量のアクセスを処理しきれずにサーバーが落ちてしまうことが考えられます。
Auto Scalingを利用することで、アクセスが増加すると自動で追加のサーバーが立ち上がり、大量のアクセスにも耐えられるようになります。その結果、サーバーがダウンすることなく、「ユーザーがオンラインショップにアクセスできない」といった事態を避けることができます。
そしてセールが終わりアクセス数が減少すると、自動で不要になったサーバーを減らしてくれるため、運用するコストを節約できます。
Auto Scalingを利用することで需要の変動に柔軟に対応することができ、常に最適なリソースでアプリケーションを運用できるようになります。
EC2 Auto Scalingのメリット
指定した数のEC2インスタンス数を維持してくれる
EC2 Auto Scalingでは、維持する最小台数、負荷がかかった時にインスタンスを増やす上限などを設定することができます。
実際の運用時はこの設定値に基づき、Auto ScalingGroupの負荷が低い時は最小台数を維持し、アクセスが増加して負荷が上がった場合には、上限値までの間で自動的にインスタンス数を増やしてくれます。
このように運用者がわざわざ自分で操作しなくても、AWS側で自動的にインスタンス数を維持してくれるのがEC2 Auto Scalingのメリットの一つです。
異常検出時、自動でインスタンスを置き換える
EC2 Auto Scalingは定期的にインスタンスのヘルスチェックを行い、インスタンスに異常が検出された場合自動的に対象のインスタンスを置き換えてくれます。この機能のおかげで、障害発生時のダウンタイムを最小限に抑えることができ、アプリケーションの可用性を高めることができます。
複数のアベイラビリティゾーン間で均等にインスタンスを配置してくれる
EC2 Auto Scalingは、設定された複数のアベイラビリティゾーン(AZ)間でEC2インスタンスを均等に分散させることで、アプリケーションの高可用性と耐障害性を実現します。Auto ScalingGroupの作成時にユーザーは複数のAZを指定でき、EC2 Auto Scalingはこの指定したAZ間でインスタンスを均等に配置しようとします。
スケールアウトするときは、インスタンスが最も少ないAZに新規起動されるよう設計されているのも特徴です。
EC2 Auto Scalingの構成要素
EC2 Auto Scalingを利用するには、3つの要素を押さえておく必要があります。
- 起動テンプレート
- インスタンス起動数の条件定義
- スケーリングポリシーの設定
起動テンプレート
EC2 Auto Scalingを設定する際、「起動テンプレート」または「起動設定」を使用してインスタンス(サーバー)の設定をします。「起動テンプレート」とは、インスタンスのタイプ、AMI(Amazon Machine Image)、キーペア、セキュリティグループなど、インスタンスの起動に必要な情報をまとめたものです。
「起動設定」も似たような目的で使用されますが、2023年6月1日以降に作成された新しいアカウントでは、コンソールからの起動設定の作成ができなくなりました。
2024年1月1日以降に作成された新しいアカウントでは、コンソール、API、CLIから起動設定を作成することができなくなっているので注意が必要です。
https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/launch-configurations.html
インスタンス起動数の条件定義
ユーザーは最小、最大、希望するキャパシティの条件を定義することができます。この条件に基づいて、Auto Scalingはスケールアウト(サーバーの追加)やスケールイン(サーバーの削除)を実行し、リソースの使用率を最適化します。
スケールについての詳細は、次の記事で解説しています。
https://envader.plus/article/37

-
希望するキャパシティ
Auto ScalingGroup作成時のインスタンス数を指定します。Auto ScalingGroupが作成されると、初めに「希望するキャパシティ」で設定した台数のインスタンスが起動します。
たとえば、キャンペーンやセール期間中にアクセス数の増加が予測される場合、希望するキャパシティを一時的に増やして対応することができます。
-
最小キャパシティ
Auto ScalingGroupが維持するEC2インスタンスの最小数を指定します。後述するスケーリングポリシーを設定し自動で台数を減らす際にも、最小キャパシティで指定した台数以下には減らさないようにしてくれます。 例として、最小キャパシティを「3」に設定した場合、これ以下に減らさないよう維持してくれます。
-
最大キャパシティ
Auto Scalingグループが起動できるEC2インスタンスの最大数を定義します。これは、負荷が上がり続けたときに自動でどれだけインスタンスを起動するかの上限を指定します。
仮に最大キャパシティを10台とした場合、負荷の増加に伴い10台までは自動でインスタンスを起動してくれます。逆に10台以上必要になった場合でも、これ以上は起動できなくなるため設定には注意が必要です。
最大キャパシティを適切に設定することで、予期しないアクセスの増加にも対応可能となり、同時に過剰なコストの発生を防ぐことができます。
スケーリングポリシーの設定
Auto ScalingではCPU使用率や過去のデータを基にしたスケーリングポリシーを設定することができます。たとえば、CPU使用率が70%を超えた場合にスケールアウトを行う、夜間の低負荷時にはインスタンス数を自動的に減らすといった条件を設定することで、リソースの使用率を自動で最適化することが可能です。
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-scale-based-on-demand.html
スケーリングポリシーは「動的スケーリング」、「予測スケーリング」、「スケジュールスケーリング」の3つに分類することができます。この中でも今回は動的スケーリングに焦点を当てます。
動的スケーリングでは以下3つのポリシーが存在します。
-
ターゲット追跡スケーリングポリシー
指定したメトリクス(CPU使用率など)が設定した値を維持するように、自動でインスタンス数を調整します。例として、CPU使用率50%を維持するよう設定した場合、このCPU使用率を保つようにインスタンスを自動で増減してくれます。
ターゲット追跡スケーリングポリシーでは、スケールアウト用、スケールイン用、2つのCloudWatchアラームが自動的に作成され、このアラームをもとにスケールが実行されます。
-
ステップスケーリングポリシー
ステップスケーリングポリシーでは、1つのメトリクスに対して複数のスケーリングの値を設定することができます。例として、CPU使用率が70%を超えた場合には2台のインスタンスを追加し、90%を超えた場合にはさらに3台のインスタンスを追加する、といった具体的なステップを設定することができます。
-
シンプルスケーリングポリシー
最も基本的な動的スケーリングの形式で、1つのメトリクスに対して1つのスケーリングの値を設定できます。
CPU使用率が50%を超えたときにインスタンスを1台追加する、というシンプルな設定になり、先述した2つのスケーリングポリシーよりも汎用性が少ないことがわかります。 公式ドキュメントでは、ターゲット追跡スケーリングポリシー、ステップスケーリングポリシーのどちらかを使用するよう推奨されています。 https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-scaling-simple-step.html#simple-scaling-policies
Terraformとは
Terraformは、HashiCorp社によって開発されたオープンソースのIaC(Infrastructure as Code)ツールで、業界ではデファクトスタンダードとされています。Terraformを使用することで、AWSのリソースをはじめとした様々なクラウドプロバイダーのリソースをコードによって管理することができます。
Terraformを利用する上で重要なtfstateファイルについては、次の記事を参照ください。
https://envader.plus/article/199
TerraformによるAuto Scalingグループの実装
このセクションでは、Terraformを使用してAmazon EC2 Auto Scalingグループを作成します。
実際にリソースを作成することになるため、料金が発生する場合がありますのでご注意ください。
プロバイダの定義
はじめに、AWSやGCPなど、どのプロバイダを使用するかを定義するため、versions.tfを作成します。
# versions.tf
terraform {
required_version = ">= 1.0.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.3.0"
}
}
}
provider "aws" {
region = "ap-northeast-1"
}
VPCの定義
次に、main.tfを作成しVPCを定義します。
VPCに対する基本的な知識は、以下の記事で解説しています。
https://envader.plus/article/76
# main.tf
locals {
region_azs = ["ap-northeast-1a", "ap-northeast-1c"]
instance_type = "t2.micro"
ami_id = "ami-02181a724aa2ad10b"
}
# VPC
resource "aws_vpc" "myapp_vpc" {
cidr_block = "10.0.0.0/16"
enable_dns_support = true
enable_dns_hostnames = true
tags = {
"Name" = "myapp_vpc"
}
}
# Subnets
resource "aws_subnet" "myapp_subnet_a" {
vpc_id = aws_vpc.myapp_vpc.id
cidr_block = "10.0.1.0/24"
availability_zone = local.region_azs[0]
tags = {
"Name" = "myapp_subnet_a"
}
}
resource "aws_subnet" "myapp_subnet_c" {
vpc_id = aws_vpc.myapp_vpc.id
cidr_block = "10.0.2.0/24"
availability_zone = local.region_azs[1]
tags = {
"Name" = "myapp_subnet_c"
}
}
# Security Group
resource "aws_security_group" "myapp_sg" {
vpc_id = aws_vpc.myapp_vpc.id
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
"Name" = "myapp_sg"
}
}Auto Scalingグループ、リソース定義の作成
resource "aws_autoscaling_group"を使ってAuto Scaling Groupを作成します。
# main.tf
# Autoscaling Group
resource "aws_autoscaling_group" "myapp_asg" {
name = "myapp-asg" # Auto Scaling Group名
max_size = 6 # 最大キャパシティ
min_size = 1 # 最小キャパシティ
desired_capacity = 4 # 希望するキャパシティ
health_check_grace_period = 300
health_check_type = "EC2"
enabled_metrics = ["GroupInServiceInstances"]
launch_template {
id = aws_launch_template.myapp_launch_template.id
version = "$Latest"
}
vpc_zone_identifier = [aws_subnet.myapp_subnet_a.id, aws_subnet.myapp_subnet_c.id]
}-
health_check_grace_period
インスタンスが起動してからヘルスチェックを開始するまでの時間を秒単位で指定します。
-
health_check_type
EC2かELBを選択することができ、EC2ではインスタンスに対するシステムステータスチェック、インスタンスステータスチェックの2つを実施します。 -
enabled_metrics
CloudWatchで監視するメトリクスを有効にします。
GroupInServiceInstancesでは、Auto Scaling Group内のインスタンスのうち、保留中(Pending)や終了(Terminated)状態ではない、正常にサービスを提供しているインスタンスの数をモニタリングします。Amazon EC2 Auto Scaling の Amazon CloudWatch メトリクス
そのほかの各パラメータ詳細は公式ドキュメントで確認しましょう。
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/autoscaling_group
起動テンプレートの作成
resource "aws_key_pair"でEC2の起動に必要なキーペアの情報を取得します。
Auto Scaling Groupを作成するためには起動テンプレートが必要です。resource "aws_launch_template”でAMI IDやインスタンスタイプなど、必要な情報を定義します。
# main.tf
# key-pair
resource "aws_key_pair" "myapp_key_pair" {
key_name = "myapp_key_pair"
public_key = file("~/.ssh/xxxxx.pub") # ローカルに保存しているキーペアのパス
}
# 起動テンプレート
resource "aws_launch_template" "myapp_launch_template" {
name = "myapp-lt"
image_id = local.ami_id # AMIのIDを指定
instance_type = local.instance_type
key_name = aws_key_pair.myapp_key_pair.key_name
network_interfaces {
associate_public_ip_address = true
security_groups = [aws_security_group.myapp_sg.id]
}Auto Scaling Policyの作成
resource "aws_autoscaling_policy"では、Auto Scaling Groupに対するスケーリングポリシーを定義しています。
policy_typeでターゲット追跡スケーリングポリシーを選択し、target_tracking_configurationを使用してスケーリングの基準となるメトリクスを指定します。
今回の設定では、Auto Scaling Groupの平均CPU使用率を50%に保つようにインスタンスの数が自動的に調整されます。平均CPU使用率が50%を超えると自動的にインスタンスが追加され、平均CPU使用率が下がると追加したインスタンスが削除されます。
# main.tf
# Autoscaling Policy
resource "aws_autoscaling_policy" "myapp_scale_out" {
name = "myapp-scale-out"
autoscaling_group_name = aws_autoscaling_group.myapp_asg.name
policy_type = "TargetTrackingScaling"
target_tracking_configuration {
predefined_metric_specification {
predefined_metric_type = "ASGAverageCPUUtilization"
}
target_value = 50.0
}
}まとめ
この記事では、AWS EC2 Auto Scalingグループを利用するために必要な知識と、Terraformを使った具体的な実装方法を解説しました。
EC2 Auto Scalingは、アプリケーションの負荷に応じてEC2インスタンスの数を自動的に増減させることで、コストの効率化、パフォーマンスの最適化を図ることができます。
Terraformを使用することで、インフラストラクチャの設定をコード化し、変更が必要な場合には迅速に、効率的に対応することが可能になります。
今回はAuto Scaling Groupのみ作成しましたが、これにELBを組み合わせることで実際の運用業務に使えるものになりますので、この記事を参考にぜひ挑戦してみてください。
【番外編】USBも知らなかった私が独学でプログラミングを勉強してGAFAに入社するまでの話

プログラミング塾に半年通えば、一人前になれると思っているあなた。それ、勘違いですよ。「なぜ間違いなの?」「正しい勉強法とは何なの?」ITを学び始める全ての人に知って欲しい。そう思って書きました。是非読んでみてください。
「フリーランスエンジニア」
近年やっと世間に浸透した言葉だ。ひと昔まえ、終身雇用は当たり前で、大企業に就職することは一種のステータスだった。しかし、そんな時代も終わり「優秀な人材は転職する」ことが当たり前の時代となる。フリーランスエンジニアに高価値が付く現在、ネットを見ると「未経験でも年収400万以上」などと書いてある。これに釣られて、多くの人がフリーランスになろうとITの世界に入ってきている。私もその中の1人だ。数年前、USBも知らない状態からITの世界に没入し、そこから約2年間、毎日勉学を行なった。他人の何十倍も努力した。そして、企業研修やIT塾で数多くの受講生の指導経験も得た。そこで私は、伸びるエンジニアとそうでないエンジニアをたくさん見てきた。そして、稼げるエンジニア、稼げないエンジニアを見てきた。
「成功する人とそうでない人の違いは何か?」
私が出した答えは、「量産型エンジニアか否か」である。今のエンジニア市場には、量産型エンジニアが溢れている!!ここでの量産型エンジニアの定義は以下の通りである。
比較的簡単に学習可能なWebフレームワーク(WordPress, Rails)やPython等の知識はあるが、ITの基本概念を理解していないため、単調な作業しかこなすことができないエンジニアのこと。
多くの人がフリーランスエンジニアを目指す時代に中途半端な知識や技術力でこの世界に飛び込むと返って過酷な労働条件で働くことになる。そこで、エンジニアを目指すあなたがどう学習していくべきかを私の経験を交えて書こうと思った。続きはこちらから、、、、

エンベーダー編集部
エンベーダーは、ITスクールRareTECHのインフラ学習教材として誕生しました。 「遊びながらインフラエンジニアへ」をコンセプトに、インフラへの学習ハードルを下げるツールとして運営されています。


関連記事
2026.02.21
Docker Compose入門|インストールからyml作成・コマンド操作まで解説
Docker Composeの基本を初心者向けにやさしく解説。インストール方法からdocker-compose.ymlの書き方、サービス・ボリューム・ネットワークの基本概念、よく使うコマンド操作まで、ステップごとに学べます。
- ハンズオン
- Docker
2024.09.22
【Terraformハンズオン】非同期呼び出しのLambda関数をデプロイしてみよう
こちらの記事では、Lambda関数の「非同期呼び出し」に焦点を絞って解説し、Terraformを使ったハンズオンを行います。
- AWS
- Terraform
- ハンズオン

2025.05.06
初心者でもサクッとDockerでアプリをデプロイする方法
この記事では、初心者でもDockerを使って簡単なWebアプリケーションをデプロイし、実際に動かせるように、基本的な流れを丁寧に解説します。さらに、アプリケーションの更新や削除方法も説明するので、Dockerを使いこなせるようになるはずです。
- Docker
- ハンズオン
2024.04.26
ECSで実現するコンテナデプロイメント AWS DOP試験対策にも
AWS DOP試験合格を目指す方や、ECSによるCICDに興味のある方へ。このハンズオン記事では、CodePipelineとECSを活用したコンテナデプロイメントを実際に実践することで、試験対策と技術習得を同時に実現します。
- AWS
- ハンズオン
- 資格