

AWS Lambdaは、必要な時に必要な時だけアプリケーションを実行できるサーバーレスサービスです。AWSが提供するLambdaを使用すれば、アプリケーションを実行するためのサーバーの構築、管理をAWSにお任せすることができます。
この記事では、Lambdaの同期呼び出し、非同期呼び出しについて解説し、IaCツールであるTerraformを使って実際にLambda関数をAWSへデプロイする方法を紹介します。
AWSを担当するインフラエンジニアとしては必要な知識となりますので、この記事で手を動かしながら理解していきましょう。
Lambdaとは
AWS Lambdaは、先述したようにAWSが提供するサーバーレスサービスの一つです。
Lambdaでは、開発者が用意したプログラムの実行環境はAWS側で用意してくれるため、開発側でのサーバー構築が不要になります。
従来であれば、EC2などのサーバーを用意し、Node.jsやPythonなどのプログラムをサーバーへインストールする必要がありました。Lambdaではこの手間を省くことができるため、サーバーの準備は気にせずにプログラムの開発に取り組むことが可能になります。
Lambdaがなぜ必要なのか、Lambdaを利用するメリットについては、以下の記事で解説していますのでご参照ください。
https://envader.plus/article/60
サーバーレスとは
「サーバーレスとは」、についても振り返ります。
「サーバーレス」という言葉から「サーバーが存在しない」と想像しがちですが、実際にはサーバーの存在を意識せずにアプリケーションを実行できる環境のことを指します。
サーバーの存在を意識しないで済むということは、構築にかかる工数やコストを削減できることはもちろん、パッチ適用やセキュリティ面の管理も不要となるため、開発者だけではなく運用者の負担を減らすことも可能となります。
サーバーレスのメリット、デメリットなどは以下の記事で詳しく解説しています。
https://envader.plus/article/36
Lambdaにおける同期呼び出しと非同期呼び出し
Lambdaはイベント駆動型のサービスで、何らかのイベント(トリガー)をきっかけにして動作します。このトリガーには大きく分けて、同期呼び出し、非同期呼び出しの2つの方法があります。
同期呼び出し
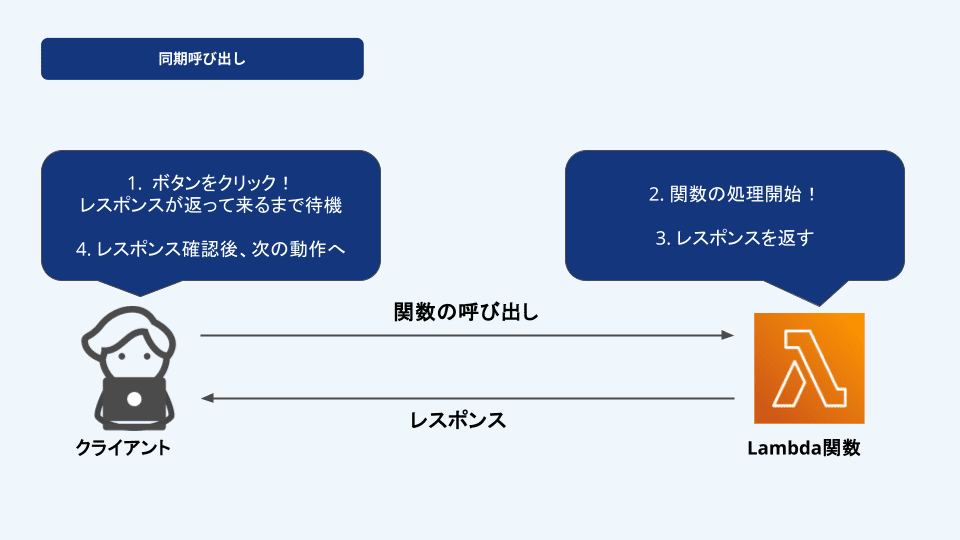
同期呼び出しは、Lambda関数を呼び出したクライアント側が関数の実行結果を待って、そのレスポンスを受け取ります。
表現を変えると、クライアントはLambda関数が処理を完了し、結果が返ってくるまで次の処理に進むことができません。
例えば、ウェブサイトでユーザーがボタンをクリックした時、そのリクエストがLambda関数に送られ、処理が終わるまで待機するようなイメージです。同期呼び出しはこの例のように、リアルタイムに処理結果を返す必要がある場面でよく使われます。
この同期呼び出しに対応しているAWSサービスには、Amazon API Gateway、Amazon Cognito、ELB(Application Load Balancer)など複数のサービスが対応しています。
同期呼び出し、非同期呼び出しに対応するサービスの種類に関しては、公式ドキュメントから確認できます。
同期呼び出しのエラー処理
同期呼び出しでは、エラーが発生した場合自動的に再試行されることはないため、クライアント側で適切にエラーを処理する必要があります。エラーメッセージをクライアントに返し、ユーザーに対して適切な表示をするなどの対策が必要になります。
例えば、Lambda関数でエラーが発生した時に、ユーザーには「システムエラーが発生しました。しばらくしてから再度お試しください」といった通知を表示するなどが考えられます。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/invocation-retries.html
非同期呼び出し
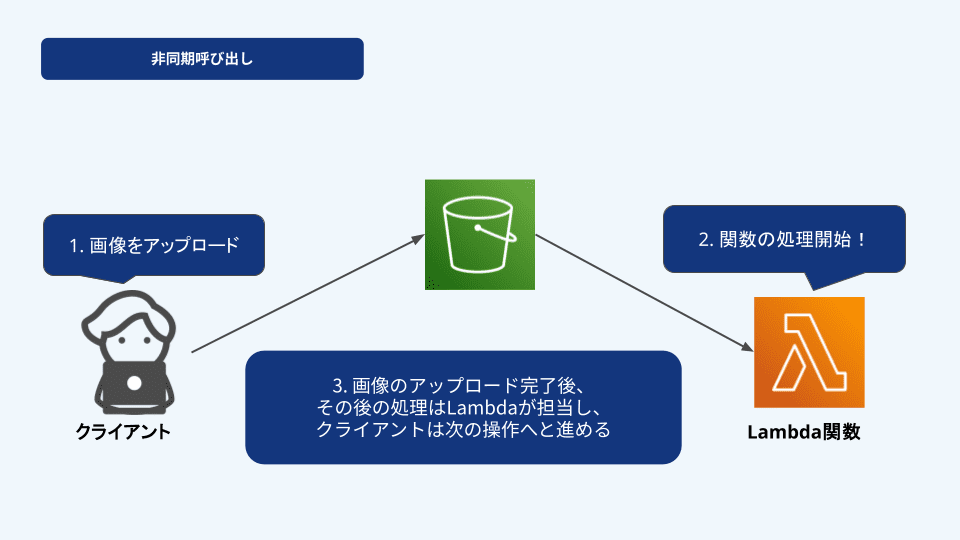
非同期呼び出しは、クライアントはLambda関数の実行結果を待たずに次の処理に進むことができます。クライアントが受け取るのは「Lambda関数が正常に呼び出された」という確認だけで、その後どう処理されるかは気にする必要がありません。結果を待たずに進行できるため、バックグラウンドの処理や、すぐに結果が必要ない処理をする場合に適しています。
例として、S3バケットに画像ファイルをアップロードした時、アップロードされたことをトリガーにLambda関数が起動する場合があります。この時、画像ファイルが無事にアップロードされたことが確認されたら、ユーザーはそのまま次の操作に進めます。
その後、Lambda関数はバックグラウンドでサムネイル画像を生成するなどの処理を実行するため、ユーザーはその処理を待つ必要がありません。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/invocation-async.html
非同期呼び出しのエラー処理
非同期呼び出しでは、エラーが発生した場合デフォルトで最大2回まで自動で再試行されます。再試行を実行してもエラーが解消されない場合は関数の実行は失敗します。
この時、失敗したイベントやメッセージを「デッドレターキュー (DLQ)」に送られるように設定することが可能です。DLQを設定しておけば、失敗した処理内容を後から確認し、どこで何が原因で失敗したのかを把握できるため、問題の特定や修正がしやすくなります。
Terraformで同期呼び出しのLambda関数をデプロイしてみよう
ここからは、Terraformを使って実際にLambda関数を作成、デプロイします。
Terraformの環境構築がまだ済んでいない方は、以下の記事を参考にTerraformのインストールやセットアップを行いましょう。
https://envader.plus/article/162
ディレクトリ構成
ディレクトリ構成は以下にしました。
.
├── lambda.zip
├── lambda_functions
│ └── hello.mjs
├── main.tf
├── output.json
├── terraform.tfstate
├── terraform.tfstate.backup
└── versions.tfデプロイするLambda関数、hello.mjsはlambda_functionsディレクトリを作成し、その配下に配置しています。
versions.tf
今回のLambda関数では、ランタイムにNodejs20.xを指定します。Nodejs20.xがサポートされたプロバイダーバージョンは5.26.0以降になります。そのため、今回はプロバイダーバージョンを5.26.0に設定しています。
詳しくは次のドキュメントを参照ください。
https://github.com/hashicorp/terraform-provider-aws/pull/34401#issuecomment-1815494193
# versions.tf
terraform {
required_version = ">= 1.0.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.26.0"
}
}
}
provider "aws" {
region = "ap-northeast-1"
}main.tf
main.tfの内容は次のように作成します。
今回はLambda関数をデプロイするため、コード量は少なめになります。
# main.tf
# IAM Policy Documentの作成
data "aws_iam_policy_document" "lambda" {
statement {
effect = "Allow"
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
}
}
# IAM Roleにポリシーをアタッチ
resource "aws_iam_role_policy_attachment" "lambda" {
role = aws_iam_role.lambda.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
# IAM Roleの作成
resource "aws_iam_role" "lambda" {
name = "lambdaExecutionRole"
assume_role_policy = data.aws_iam_policy_document.lambda.json
}
# Lambda関数の作成
resource "aws_lambda_function" "hello_lambda" {
function_name = "nodejs_hello_lambda" # 関数名
role = aws_iam_role.lambda.arn # 作成したIAM Role
handler = "hello.handler" # hello.mjsのhandler関数を呼び出すという意味
runtime = "nodejs20.x" # Lambdaのランタイム
timeout = "10" # タイムアウト値(秒)
filename = data.archive_file.main.output_path # zipファイルのパス
source_code_hash = data.archive_file.main.output_base64sha256 # ソースコードの変更検出に使用するハッシュ値。
depends_on = [ data.archive_file.main ] # ZIPファイルのアーカイブが完了してからLambda関数を作成する。
}
# Lambda関数のソースコードをZIPファイルにアーカイブする
data "archive_file" "main" {
type = "zip"
source_dir = "${path.module}/lambda_functions"
output_path = "${path.module}/lambda.zip"
}source_code_hashは、Lambda関数のソースコードに変更があったかどうかを判断するために必要になります。.mjsファイルに変更があった場合この値が変更され、ファイルの内容に差分があることを判断します。
# Lambda関数のソースコードをZIPファイルにアーカイブする
data "archive_file" "main" {
type = "zip"
source_dir = "${path.module}/lambda_functions"
output_path = "${path.module}/lambda.zip"
}続いて archive_file は、指定したディレクトリにあるソースコードをZIPファイルとしてまとめ、Lambda関数に渡せる形式に変換します。
${path.module}はTerraformモジュールが配置されているディレクトリを意味しており、そのディレクトリの/lambda_functions以下のファイルをzip化するよう指定しています。
output_pathでは、作成したzipファイルの保存先を指定します。今回のケースでは、main.tfと同じディレクトリにzipファイルが作成されます。
今回はシンプルなディレクトリ構成のため、${path.module}でプロジェクトのルートディレクトリにzipファイルが作成されますが、モジュール化していた場合どうなるかの参考例を以下に記載します。
data "archive_file" "main" {
type = "zip"
source_dir = "${path.module}/lambda_functions"
output_path = "${path.module}/lambda.zip"
}
# module化していた場合
/my-terraform-project
├── main.tf # ルートディレクトリファイル (モジュール呼び出し)
├── versions.tf
├── output.json
├── terraform.tfstate
├── terraform.tfstate.backup
├── /modules # モジュールをまとめるディレクトリ
│ └── /lambda # Lambdaモジュールディレクトリ
│ ├── main.tf
│ ├── lambda.zip # ${path.module}/lambda.zip
│ └── lambda_functions # ${path.module}/lambda_functions以下のファイルをアーカイブ
│ └── hello.mjs hello.mjs
最後にLambda関数の中身を作成します。今回は簡単なレスポンスを確認したいので、関数が実行されたらメッセージを返すシンプルな内容となっています。
ランタイムにnodejs20.xを指定するため、拡張子は.mjsになります。
// hello.mjs
export async function handler(event) {
return {
statusCode: 200,
body: JSON.stringify('Hello from Lambda deployed by Terraform!!'),
};
}ファイルの作成完了後、applyしてリソースを作成します。
terraform apply同期呼び出し関数のテスト
今回はコンソールからではなく、AWS CLIを使用して作成した関数を呼び出し、メッセージが返ってくるかを確認します。
コマンドは以下を実行します。
aws lambda invoke --function-name <関数名> --payload '{}' output.json関数名には、作成したLambda関数名を指定します。—-payloadでは、作成した関数に渡す値がある場合{}の中に値を記述します。
output.jsonとすることで、実行結果がjson形式で保存されます。
関数の実行が成功した場合、以下のようにレスポンスが表示されます。
# 関数の呼び出し
aws lambda invoke --function-name nodejs_hello_lambda --payload '{}' output.json
# 以下レスポンス
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}output.jsonにレスポンスの内容が保存されていることを確認します。
cat output.json
{"statusCode":200,"body":"\"Hello from Lambda deployed by Terraform!!\""}まとめ
この記事では、Lambda関数の同期呼び出し、非同期呼び出しについて解説しました。
同期呼び出しでは、クライアントがLambda関数の実行結果を待ち、そのレスポンスを受け取るためリアルタイムな処理が求められる場面でよく使われます。
一方の非同期呼び出しは、クライアントがLambda関数の処理結果を待たずに次の操作に進むことができるため、バックグラウンド処理や時間がかかる処理に適しています。
さらにTerraformハンズオンとして、同期呼び出しのLambda関数をデプロイするハンズオンを行いました。今回のハンズオンを通じて、Lambda関数の基本的な仕組みや実装方法を学ぶことができたと思います。これをベースに、さらに高度なLambda関数の実装に挑戦してみてください。
参考資料
以下のリンクは、この記事で説明した手順や概念に関連する参考資料です。より詳しく学びたい方は、ぜひご参照ください。
【番外編】USBも知らなかった私が独学でプログラミングを勉強してGAFAに入社するまでの話

プログラミング塾に半年通えば、一人前になれると思っているあなた。それ、勘違いですよ。「なぜ間違いなの?」「正しい勉強法とは何なの?」ITを学び始める全ての人に知って欲しい。そう思って書きました。是非読んでみてください。
「フリーランスエンジニア」
近年やっと世間に浸透した言葉だ。ひと昔まえ、終身雇用は当たり前で、大企業に就職することは一種のステータスだった。しかし、そんな時代も終わり「優秀な人材は転職する」ことが当たり前の時代となる。フリーランスエンジニアに高価値が付く現在、ネットを見ると「未経験でも年収400万以上」などと書いてある。これに釣られて、多くの人がフリーランスになろうとITの世界に入ってきている。私もその中の1人だ。数年前、USBも知らない状態からITの世界に没入し、そこから約2年間、毎日勉学を行なった。他人の何十倍も努力した。そして、企業研修やIT塾で数多くの受講生の指導経験も得た。そこで私は、伸びるエンジニアとそうでないエンジニアをたくさん見てきた。そして、稼げるエンジニア、稼げないエンジニアを見てきた。
「成功する人とそうでない人の違いは何か?」
私が出した答えは、「量産型エンジニアか否か」である。今のエンジニア市場には、量産型エンジニアが溢れている!!ここでの量産型エンジニアの定義は以下の通りである。
比較的簡単に学習可能なWebフレームワーク(WordPress, Rails)やPython等の知識はあるが、ITの基本概念を理解していないため、単調な作業しかこなすことができないエンジニアのこと。
多くの人がフリーランスエンジニアを目指す時代に中途半端な知識や技術力でこの世界に飛び込むと返って過酷な労働条件で働くことになる。そこで、エンジニアを目指すあなたがどう学習していくべきかを私の経験を交えて書こうと思った。続きはこちらから、、、、

エンベーダー編集部
エンベーダーは、ITスクールRareTECHのインフラ学習教材として誕生しました。 「遊びながらインフラエンジニアへ」をコンセプトに、インフラへの学習ハードルを下げるツールとして運営されています。


関連記事

2026.03.14
AWS IAMユーザーとは?グループ・ロールとの違いと使い方を解説
AWS IAMユーザーとは、AWSリソースへのアクセスを管理するためのID単位です。グループやロールとの違い、作成手順からアクセスキーの安全な管理方法まで解説します。
- インフラエンジニア
- AWS

2025.11.21
【Terraformハンズオン】EC2のスケールアウトをスケジュールしてみよう
こちらの記事では、IaCツールのTerraformを使用し、EC2インスタンスのスケールアウトをスケジュールして実行する方法を解説します。
- AWS
- ハンズオン
2023.01.08
【AWS】Amazon S3で静的ホスティングする理由
今回はS3の注目機能である静的ホスティングについて、導入する理由や主な使用用途について解説を行います。
- AWS

2024.05.29
AWSの監視戦略 主要サービスのメトリクスとアラート設定を理解する
AWSクラウド環境を最大限に活用するためには、リソースの監視とアラート設定が不可欠です。
- AWS