「サーバレスにはサーバーがない?」
近年、注目を集める「サーバレス」。なんだか難しそう…と感じていませんか?実は、サーバレスはサーバーが無いという意味の「サーバーレス」ではなく「サーバー管理レス」なんです。つまり、サーバーの管理はクラウドに任せて、開発者はコードを書くだけでアプリが開発できてしまうんです。
サーバレスの主なサービスには、AWS Lambda、Azure Functions、Google Cloud Functionsなどがありますが、このハンズオンではAWSのサービスを使用します。
サーバレスのメリットとは何か?
- 開発が簡単
- コスト削減
- リリースがスピーディ
- 自動スケーリング
サーバレスコンピューティングの最大のメリットは、インフラの管理から解放されることです。開発者はサーバーのプロビジョニングや保守に関する心配をする必要がなく、アプリケーションのコードの作成とその実行に専念できます。より迅速にアプリケーションを市場に投入することが可能となり、イノベーションの速度を高めることができます。
どのような問題を解決できるのか?
サーバレスアーキテクチャは特に可変的なトラフィックがあるアプリケーションに最適です。例えば、プロモーション期間中にアクセスが増えるEコマースサイトやイベント駆動型のアプリケーションなど、需要が予測しにくい場合でも、サーバレスは自動でスケーリングを行い、必要なリソースを確保します。過剰なリソースを確保するコストを削減しつつ、ユーザーに対して一貫したパフォーマンスを提供することが可能です。さらに、IoTデバイスの制御や機械学習のモデル推論など、イベントベースのアプリケーションでも活用できます。
- Webアプリケーション
- モバイルアプリ
- データ分析
- IoT
- 機械学習
など。
ハンズオンで作成するアプリケーションの概要
このハンズオンでは、「投票アプリケーション」を作成します。このアプリケーションは、ユーザーが異なる選択肢に投票できるシンプルなウェブベースのアプリケーションです。主なコンポーネントは以下の通りです。
-
AWS Lambda
バックエンドロジックを実行します。ユーザーの投票を受け取り、処理して、結果をDynamoDBに保存します。
-
API Gateway
フロントエンドとバックエンド間の通信を仲介します。Lambda関数にHTTPリクエストをルーティングし、フロントエンドにデータを返します。
-
DynamoDB
投票データを保存するAWSのNoSQLデータベースサービスです。高速でスケーラブルなデータベースオプションを提供します。
ユーザーはウェブインターフェースを介して投票を行い、リアルタイムで投票結果を確認することができます。このプロセスを通じて、サーバレスアーキテクチャでのアプリケーション開発の流れを学ぶことができます。
## AWSアカウントの作成と必要なサービスの概説
サーバレスアプリケーションを開発するための最初のステップは、AWSアカウントの作成と必要なサービスの理解です。AWSアカウントが準備している人はスキップしてください。
ここでは、AWSアカウントの作成方法と、このハンズオンで使用する主要なAWSサービス(AWS Lambda、API Gateway、DynamoDB)の基本的な概説を行います。
AWSアカウントの作成
-
アカウント作成
AWS公式ウェブサイトにアクセスし、「ルートユーザーのEメールアドレス」と「AWSアカウント名」を入力後、「認証コードをEメールアドレスに送信」をクリックします。
必要な情報(メールアドレス、パスワード、アカウント名など)を入力し、指示に従ってアカウント登録を完了させます。
登録時にはクレジットカード情報が求められますが、多くのサービスは無料枠内で利用可能です。
-
ログインと初期設定
アカウント作成後、AWSマネジメントコンソールにログインします。初回ログイン時には、基本的な設定を行う必要があります。必要に応じて支払い情報やセキュリティ設定(MFA: 多要素認証など)を確認・設定します。
必要なサービスの概説
-
AWS Lambda
AWS Lambdaは、コードをサーバーのプロビジョニングや管理なしに実行できるサービスです。イベントに応じてコードが自動的に実行され、使用した計算リソースの量に基づいて課金されます。 Lambdaは多様なトリガー(HTTPリクエスト、データベースの変更イベントなど)に対応し、API GatewayやDynamoDBとの統合が容易です。
-
Amazon API Gateway
API Gatewayは、HTTPリクエストをLambda関数や他のAWSサービスへルーティングするためのサービスです。REST APIやWebSocket APIを簡単に作成、公開、保守、監視、セキュアにすることができます。
このサービスを通じて、クライアントアプリケーション(ウェブまたはモバイルアプリ)からのリクエストを受け取り、適切なバックエンドサービスに転送します。
-
Amazon DynamoDB
DynamoDBは完全マネージド型のNoSQLデータベースサービスで、高速で予測可能なパフォーマンスを提供します。大規模なデータセットに対しても、ミリ秒単位でのレスポンスタイムを保証します。
データの自動スケーリング、バックアップ、セキュリティが提供され、サーバーレスアプリケーションのデータストレージに最適です。
これらのサービスを組み合わせることで、サーバレスアーキテクチャに基づいた効果的なアプリケーションを構築できます。
アプリケーションの開発
ここでは、AWSマネジメントコンソールを使用して、サーバレス投票アプリケーションの主要コンポーネントであるLambda関数、API Gateway、およびDynamoDBテーブルを作成する具体的な手順を説明します。
1. Lambda関数の作成
1.1 AWSマネジメントコンソールにログイン
- AWSマネジメントコンソールにアクセスして、作成したアカウントでログインします。
1.2 Lambda関数の作成

「サービス」メニューから「Lambda」を選択し、「関数の作成」ボタンをクリックします。 「関数の作成」オプションで「一から作成」を選び、関数名を設定します。例えば「VoteFunction」とします。
-
ランタイム選択
使用するプログラミング言語を選択します。今回は「Python 3.12」(2024年4月時点)を使用します。「アーキテクチャ」は変更しません。
-
アクセス権限
「デフォルトの実行ロールの変更」オプションは特に変更せず、Lambda関数がDynamoDBとのやり取りを許可するロールを自動的に作成させます。
「詳細設定」は変更せず、「関数の作成」をクリックして、Lambda関数のエディタを開きます。
1.3 Lambda関数のコードを書く
Lambdaコードエディタに以下のようなサンプルコードを入力し「Deploy」します。このコードは、DynamoDBに投票データを保存するシンプルな処理です。
import json
import boto3
from botocore.exceptions import ClientError
def lambda_handler(event, context):
# DynamoDB リソースの取得
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('Votes')
try:
# eventから投票データを読み込む
vote = json.loads(event['body'])
if 'id' not in vote or 'count' not in vote:
raise ValueError("Missing 'id' or 'count' in the payload")
# DynamoDBにデータを書き込む
response = table.put_item(
Item={
'voteId': vote['id'],
'voteCount': vote['count']
}
)
# 正常にデータが書き込まれた場合のレスポンス
return {
'statusCode': 200,
'body': json.dumps('Vote recorded successfully!')
}
except ValueError as e:
# パラメータエラーの場合
return {
'statusCode': 400,
'body': json.dumps(str(e))
}
except ClientError as e:
# DynamoDBへの書き込みエラーの場合
return {
'statusCode': 500,
'body': json.dumps("Failed to write data to DynamoDB: " + str(e))
}
except Exception as e:
# その他のエラー
return {
'statusCode': 500,
'body': json.dumps("An unknown error occurred: " + str(e))
}2. API Gatewayの設定
2.1 API Gatewayの作成

- 「サービス」から「API Gateway」を選択
- 「REST API」を選択し、「構築」ボタンを押下
- 「新しいAPI」を選択し、APIの名前(例:「VotingAPI」)と入力
- 「APIを作成」をクリックしてAPIを作成
2.2 リソースとメソッドの設定
API Gatewayで新しいリソースにPOSTメソッドを追加し、リクエストをLambda関数にルーティングする設定について、以下に具体的な手順を説明します。このステップはAPI Gatewayでエンドポイントを設定し、外部のリクエストを受け取ってLambda関数をトリガーするためです。
2.2.1 リソースの追加
-
API Gatewayコンソールにアクセス
AWSマネジメントコンソールにログインし、「サービス」から「API Gateway」を選択します。
-
作成済みのAPIを選択
一覧から、設定したいAPIをクリックして開きます。
-
新しいリソースの追加
APIのダッシュボードで「リソースの作成」を選択します。
「リソース名」(例:
vote)を入力し、リソースの作成を完了します。
2.2.2 POSTメソッドの追加
-
新しく作成したリソースを選択
リソースツリーから、新しく追加したリソース(例:
/vote)をクリックします。 -
POSTメソッドの設定
リソースの詳細ページで「メソッドの作成」を選択します。
表示されるメソッド一覧で「POST」を選びます。
2.2.3 POSTメソッドの統合設定
-
統合タイプの選択
統合タイプとして「Lambda関数」を選択します。
「Lambdaリージョン」で、Lambda関数がデプロイされたリージョンを選択します(例:
ap-northeast-1)。 -
Lambda関数の指定
- 「Lambda関数」のフィールドに、統合するLambda関数の名前を入力します(例:
VoteFunction)。
- 「Lambda関数」のフィールドに、統合するLambda関数の名前を入力します(例:
-
Lambdaプロキシ統合をオン
-
設定の保存と確認
全ての設定を確認し、問題がなければ「保存」をクリックしてPOSTメソッドの設定を完了します。
これで、API Gatewayの特定のリソース(この例では /vote)にPOSTメソッドが追加され、指定したLambda関数にリクエストがルーティングされるようになります。これにより、クライアントがAPIエンドポイントにPOSTリクエストを送信すると、直接Lambda関数がトリガーされ、処理が実行される流れが確立されます。
3. DynamoDBテーブルの作成
3.1 テーブルの作成

「サービス」から「DynamoDB」を選択し、「テーブルの作成」をクリックします。 テーブル名を「Votes」とし、パーティションキーを「voteId」(文字列型)として設定します。 「テーブルの作成」をクリックしてテーブルを作成します。
3.2 IAMロールの設定
Lambda関数にDynamoDBテーブルへのアクセス権を付与するために、Lambda関数の実行ロールに適切なポリシーを追加します。ポリシーはDynamoDBテーブルへの読み書き権限を含める必要があります。以下の手順で設定を行います。
-
IAMコンソールより実施
AWSマネジメントコンソールの「サービス」メニューから「IAM」を選択します。
-
Lambda関数のロールを検索
「ロール」セクションを開き、Lambda関数作成時に自動生成されたロールを検索します。作成したLambda名で検索してください。
-
ポリシーのアタッチ
ロールをクリックして詳細画面を開き、「許可を追加」から「ポリシーをアタッチ」をクリックします。 「AmazonDynamoDBFullAccess」ポリシーを検索し、選択してアタッチします。これにより、Lambda関数がDynamoDBの全テーブルに対して読み書きが可能となります。
※本来はセキュリティを強化するために、必要な操作のみを許可するカスタムポリシーを作成することが推奨されます。
すべての設定が完了したら、アプリケーションをテストして動作を確認します。
アプリケーションのデプロイ
API GatewayでAPIをデプロイ
- API Gatewayのコンソールで、作成したAPIを選択
- 「APIをデプロイ」を選択
- 「新しいステージの作成」を選び、ステージ名を入力(例:prod)
- 「デプロイ」ボタンをクリック
以上の操作でエンドポイントが公開され、外部からアクセスできるようになります。
APIエンドポイントの確認
デプロイが完了すると、API GatewayはエンドポイントURLを提供します。このURLは、アプリケーションにアクセスするためのものです。
「URLを呼び出す」というところに表示されているものに/voteをつけます。
https://{api-id}.execute-api.{region}.amazonaws.com/{stage}/vote## アプリケーションのテスト
テストの実施
テストには次の2通りのうち、好きな方で実施してください。
-
Postmanの使用
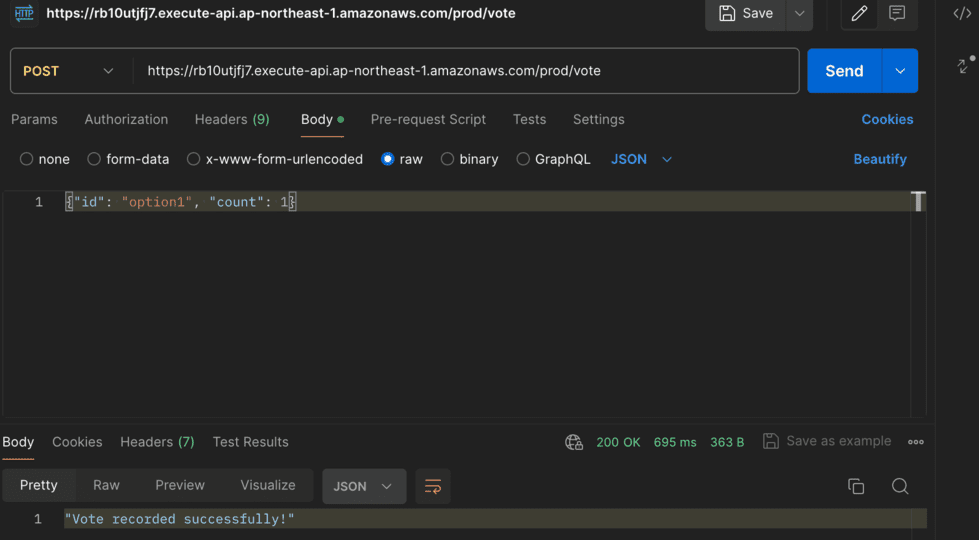
- Postmanを開き、新しいリクエストを作成
- メソッドを「POST」に設定し、デプロイしたAPIのエンドポイントURLを入力
- ヘッダーに
Content-Type: application/jsonを設定 - リクエストボディにJSON形式でデータを入力(例:
{"id": "option1", "count": 1})し、送信
-
curlの使用
- ターミナルまたはコマンドプロンプトを開き、以下のcurlコマンドを実行
curl -X POST -H "Content-Type: application/json" -d '{"id": "option1", "count": 1}' [APIエンドポイントURL]
- ターミナルまたはコマンドプロンプトを開き、以下のcurlコマンドを実行
結果の検証
正常にリクエストが処理された場合、Lambda関数からのレスポンスが返されます(例:「Vote recorded successfully!」)。
DynamoDBコンソールにアクセスし、Votesテーブルを確認して、データが正しく挿入されているかを検証します。
### エラーハンドリングの確認
不正なデータ(例: 不正なJSON形式や、定義されていないキーを含むデータ)を送信して、エラーメッセージが適切に返されるかをテストします。
このハンズオンで理解したこと
このハンズオンを通じて、AWSのサーバレスアーキテクチャを利用して簡単な投票アプリケーションを開発しました。主要なコンポーネントであるAWS Lambda、API Gateway、DynamoDBを活用し、バックエンドの構築、デプロイ、テストを行いました。
主なポイントは以下の通りです。
-
AWS Lambdaの活用
サーバー管理の必要がなく、コードの実行に集中できました。
-
API Gatewayの統合
セキュアでスケーラブルなAPIを提供し、フロントエンドとバックエンドを接続しました。
-
DynamoDBによるデータ管理
高速でスケーラブルなNoSQLデータベースを使ってアプリケーションデータを管理しました。
-
エラーハンドリングの実装
予期せぬエラーや不正な入力に適切に対応するため、エラー処理を組み込みました。
-
デプロイメントとテスト
実際のデプロイプロセスを踏み、Postmanやcurlを使ってAPIをテストしました。
このハンズオンを通して、サーバレスアーキテクチャの基本的な活用方法を理解することができました。次のステップでは、より複雑なサーバレスアプリケーションの設計や実装について学んでいきましょう。
【番外編】USBも知らなかった私が独学でプログラミングを勉強してGAFAに入社するまでの話

プログラミング塾に半年通えば、一人前になれると思っているあなた。それ、勘違いですよ。「なぜ間違いなの?」「正しい勉強法とは何なの?」ITを学び始める全ての人に知って欲しい。そう思って書きました。是非読んでみてください。
「フリーランスエンジニア」
近年やっと世間に浸透した言葉だ。ひと昔まえ、終身雇用は当たり前で、大企業に就職することは一種のステータスだった。しかし、そんな時代も終わり「優秀な人材は転職する」ことが当たり前の時代となる。フリーランスエンジニアに高価値が付く現在、ネットを見ると「未経験でも年収400万以上」などと書いてある。これに釣られて、多くの人がフリーランスになろうとITの世界に入ってきている。私もその中の1人だ。数年前、USBも知らない状態からITの世界に没入し、そこから約2年間、毎日勉学を行なった。他人の何十倍も努力した。そして、企業研修やIT塾で数多くの受講生の指導経験も得た。そこで私は、伸びるエンジニアとそうでないエンジニアをたくさん見てきた。そして、稼げるエンジニア、稼げないエンジニアを見てきた。
「成功する人とそうでない人の違いは何か?」
私が出した答えは、「量産型エンジニアか否か」である。今のエンジニア市場には、量産型エンジニアが溢れている!!ここでの量産型エンジニアの定義は以下の通りである。
比較的簡単に学習可能なWebフレームワーク(WordPress, Rails)やPython等の知識はあるが、ITの基本概念を理解していないため、単調な作業しかこなすことができないエンジニアのこと。
多くの人がフリーランスエンジニアを目指す時代に中途半端な知識や技術力でこの世界に飛び込むと返って過酷な労働条件で働くことになる。そこで、エンジニアを目指すあなたがどう学習していくべきかを私の経験を交えて書こうと思った。続きはこちらから、、、、

エンベーダー編集部
エンベーダーは、ITスクールRareTECHのインフラ学習教材として誕生しました。 「遊びながらインフラエンジニアへ」をコンセプトに、インフラへの学習ハードルを下げるツールとして運営されています。


関連記事
2024.04.06
[ハンズオン]AWS Backupで作成したAMIをLambdaを使用して起動テンプレートに適用
この記事では、AWS上でのリソース管理を自動化する方法を実践的に解説します。特に、開発環境やプロダクション環境におけるデプロイメントプロセスの簡素化や、ディザスタリカバリ準備の一環として、最新のAMIを定期的に起動テンプレートに適用する自動化手法を紹介します。
- AWS
- インフラエンジニア
- ハンズオン

2024.10.17
AWS Lambdaの基本 Lambda関数のバージョン管理を理解しよう
この記事では、Lambda関数の中でも「バージョン管理」について解説していきます。
- AWS
- ハンズオン

2024.04.14
DockerにGoでREST APIのTODOアプリを作るとDockerと仲良くなれる
今回は、「Dockerを使ってみたいけどよくわからない」という人を対象に、Docker上にGoを使ってREST APIで操作するTODOアプリケーションを作成することで、Dockerの操作に慣れていきましょう。
- ハンズオン
- Docker
- go
2024.06.17
【Terraformハンズオン】AWS CloudFront&ALB構成を実現しよう
この記事では、CloudFrontとは何かを解説し、IaC(Infrastructure as Code)を実現するためのツールであるTerraformを使ってCloudFrontを構築するまでのハンズオンを行います。
- AWS
- ハンズオン
- Terraform