はじめに
こんにちは、エンジニア、エンジニア志望者の皆さん。プログラミング学習捗っていますか?新しい技術を学ぶのは楽しいですよね。しかし、新しい概念やツールを理解するのは時に大変なこともあります。今回取り上げるのは、最近注目を集めているGraphQLです。これまでのREST APIに代わる新しいアプローチとして、多くの開発者が採用し始めています。
GraphQLは、データを効率的に取得し、必要な情報だけを簡単に取得できる優れたツールです。この記事では、GraphQLの基礎を学び、簡単なクエリを実行する方法を紹介します。これを通じて、皆さんがGraphQLの魅力を理解し、実際に使いこなせるようになることを目指します。
では、GraphQLの基礎について詳しく見ていきましょう。
GraphQLの基礎
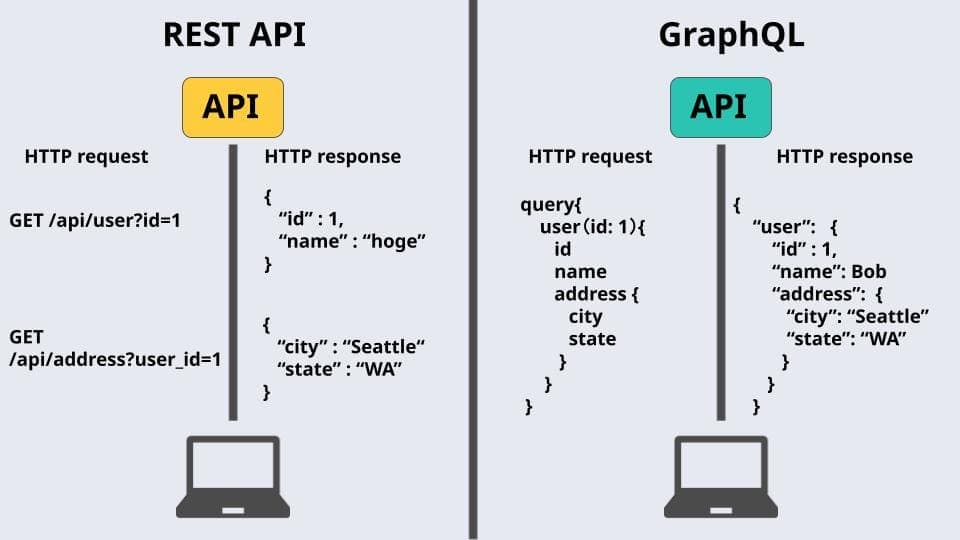
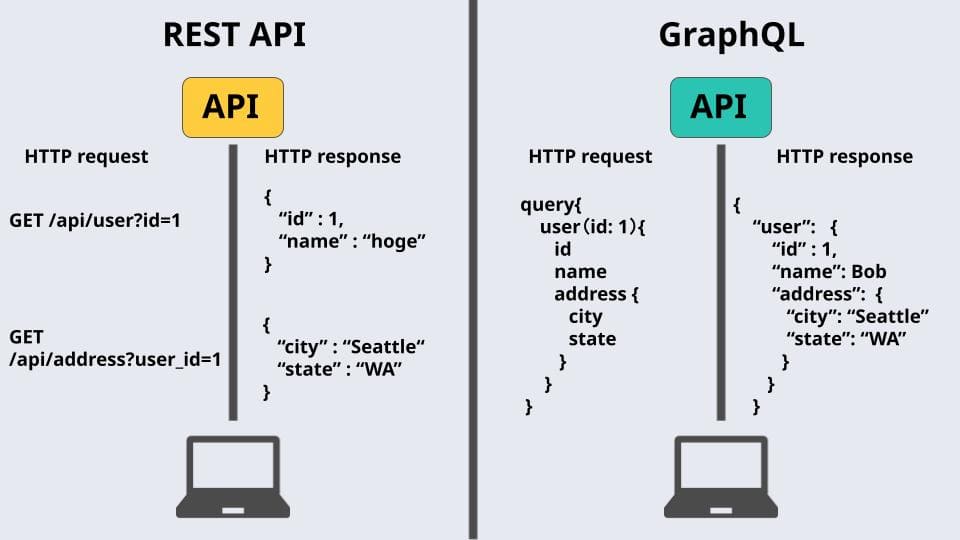
GraphQLは、Facebookによって開発されたクエリ言語であり、REST APIの代替として使われることが多いです。従来のREST APIでは、複数のエンドポイントからデータを取得する必要がありましたが、GraphQLでは単一のエンドポイントから必要なデータを一度に取得できます。GraphQLの主な特徴は以下の通りです。
-
スキーマ
スキーマは、データの構造とその関係を定義します。例えば、ユーザーや投稿などのデータタイプを定義し、それらの属性や関係性をスキーマで示します。クライアントとサーバー間のデータのやり取りが明確になります。
type User { id: ID! name: String! email: String! } type Post { id: ID! title: String! author: User } type Query { users: [User] posts: [Post] } -
クエリ
クエリは、クライアントが必要なデータを要求する方法です。GraphQLクエリは、必要なフィールドを指定してデータを取得できます。例えば、以下のクエリはすべてのユーザーの名前とメールアドレスを取得します。
query { users { name email } } -
ミューテーション
ミューテーションは、データの作成、更新、削除を行うための操作です。例えば、新しいユーザーを追加するミューテーションは以下のようになります。
mutation { addUser(name: "Charlie", email: "charlie@example.com") { id name email } } -
サブスクリプション
サブスクリプションは、リアルタイムでデータの変更を通知します。例えば、新しい投稿が追加されたときに通知を受け取るサブスクリプションは以下のようになります。
subscription { newPost { id title author { name } } } -
リゾルバ
リゾルバは、クエリやミューテーションの結果を生成する関数です。リゾルバは、クエリで要求されたデータをどのように取得するかを定義します。例えば、以下のリゾルバは、すべてのユーザーを返す関数です。
const resolvers = { Query: { users: () => { // データソースからユーザーリストを取得して返す return users; }, posts: () => { // データソースから投稿リストを取得して返す return posts; }, }, Mutation: { addUser: (_, { name, email }) => { const newUser = { id: String(users.length + 1), name, email }; users.push(newUser); return newUser; }, }, };
リゾルバをウェイターに例えるとわかりやすいです。レストランで料理を注文するとき、ウェイターが注文を受けてキッチンに伝え、料理をテーブルに持ってきてくれます。同様に、クライアントがGraphQLクエリを送信すると、リゾルバがそのリクエストを処理し、適切なデータを返します。
これらの特徴により、GraphQLは柔軟で効率的なデータ取得方法を提供し、クライアントが必要とするデータを簡単に取得できます。次に、環境のセットアップ方法について見ていきましょう。
なぜREST APIの代わりにみなされているのか
GraphQLがREST APIの代替としてみなされる理由を理解するために、まずREST APIの歴史とその課題について簡単に説明します。
別の記事でも説明していますのでご参照ください。
https://envader.plus/article/87
REST APIの歴史と課題
REST(Representational State Transfer)は、2000年にRoy Fieldingの博士論文で紹介されたアーキテクチャスタイルです。REST APIは、HTTPプロトコルを使用してクライアントとサーバー間でリソースを交換する方法を定義しています。ウェブアプリケーションの開発が大幅に簡素化され、多くのウェブサービスがREST APIを採用しました。
しかし、REST APIにはいくつかの課題があります。
-
複数のエンドポイント
データを取得するために複数のエンドポイントを呼び出す必要があるため、効率が悪いことがあります。例えば、ユーザー情報とその投稿を取得するために、
/usersと/postsの2つのエンドポイントを呼び出さなければならない場合があります。 -
過剰データ取得
必要以上のデータを取得することが多く、ネットワーク帯域幅を無駄に消費します。例えば、特定のユーザーの名前だけが欲しい場合でも、REST APIでは全ユーザーの情報を取得しなければならないことがよくあります。
-
柔軟性の欠如
クライアントが必要とするデータの形式や量を細かく指定できないため、柔軟性に欠けます。REST APIでは、エンドポイントごとに返されるデータが固定されているため、クライアントが求める情報だけを取得するのが難しい場合があります。
GraphQLの誕生
GraphQLは、これらの課題を解決するためにFacebookによって2012年に内部プロジェクトとして開発されました。Facebookのエンジニアたちは、モバイルアプリケーションの開発においてREST APIの限界に直面し、より効率的で柔軟なデータ取得方法が必要であると感じました。その結果、GraphQLが誕生し、2015年にオープンソースとして公開されました。
GraphQLの利点
GraphQLは以下の利点を持つため、REST APIの代替として広く採用されています。
-
単一のエンドポイント
すべてのデータ取得や操作を単一のエンドポイントで行うことができます。例えば、
/graphqlという1つのエンドポイントでユーザー情報や投稿情報を取得できます。 -
必要なデータのみ取得
クエリを使用して必要なフィールドだけを取得できるため、過剰なデータ取得を避けられます。例えば、ユーザーの名前とメールアドレスだけを取得するクエリを作成できます。
query { users { name email } } -
型システム
スキーマでデータの構造を明確に定義するため、開発者がAPIの使用方法を理解しやすくなります。スキーマによって、どのデータがどの形式で取得できるかが明確になるため、バグの発見も容易になります。
-
リアルタイム更新
サブスクリプションを使用してデータの変更をリアルタイムで通知できます。例えば、新しい投稿が追加されたときにクライアントに通知することができます。
subscription { newPost { id title author { name } } }
これらの利点により、GraphQLは柔軟で効率的なデータ取得方法を提供し、クライアントが必要と
するデータを簡単に取得できます。次に、環境のセットアップ方法について見ていきましょう。
環境のセットアップ
まずは、GraphQLの環境をセットアップしましょう。以下の手順に従ってください。
-
Node.jsとnpmのインストール
Node.jsがインストールされていない場合は、公式サイトからダウンロードしてインストールしてください。npmはNode.jsと一緒にインストールされます。
-
新しいプロジェクトディレクトリの作成
ターミナルを開き、任意の場所に新しいプロジェクトディレクトリを作成します。ここでは、
my-graphql-projectというディレクトリを作成します。mkdir my-graphql-project cd my-graphql-project -
プロジェクトの初期化
npm init -yコマンドを実行して、プロジェクトを初期化します。これにより、package.jsonファイルが作成されます。npm init -y -
必要なパッケージのインストール
Apollo ServerとGraphQLのパッケージをインストールします。
npm install apollo-server graphql -
プロジェクト構造の作成
プロジェクトディレクトリ内に以下のような構造を作成します。
my-graphql-project/ ├── node_modules/ ├── package.json └── index.jsindex.jsファイルは、GraphQLサーバーのエントリーポイントとなります。
簡単なクエリ例
次に、簡単なGraphQLサーバーをセットアップしてみましょう。以下のサンプルコードを使用します。
// Apollo Serverとgqlをインポート
const { ApolloServer, gql } = require('apollo-server');
// スキーマ定義:ユーザーと投稿のデータタイプ、およびクエリとミューテーションを含む
const typeDefs = gql`
type User {
id: ID!
name: String!
email: String!
}
type Post {
id: ID!
title: String!
author: User
}
type Query {
users: [User]
user(id: ID!): User
posts: [Post]
}
type Mutation {
addUser(name: String!, email: String!): User
}
`;
// サンプルデータ:ユーザーと投稿のデータを含む配列
let users = [
{ id: '1', name: 'Alice', email: 'alice@example.com' },
{ id: '2', name: 'Bob', email: 'bob@example.com' },
];
let posts = [
{ id: '1', title: 'GraphQL Introduction', author: users[0] },
{ id: '2', title: 'GraphQL vs REST', author: users[1] },
];
// リゾルバー定義:クエリとミューテーションのリクエストに対してデータを返す関数
const resolvers = {
Query: {
users: () => users,
user: (_, { id }) => users.find(user => user.id === id),
posts: () => posts,
},
Mutation: {
addUser: (_, { name, email }) => {
const newUser = { id: String(users.length + 1), name, email };
users.push(newUser);
return newUser;
},
},
};
// Apollo Serverの初期化と起動
const server = new ApolloServer({ typeDefs, resolvers });
server.listen().then(({ url }) => {
console.log(`Server ready at ${url}`);
});このコードを使って、GraphQLサーバーを立ち上げ、基本的なクエリを実行できます。以下でコードの各部分を詳しく説明します。
スキーマ定義
スキーマは、GraphQLサーバーがクエリに応じてどのようなデータを提供するかを定義します。ここでは、ユーザーと投稿のデータタイプ、およびそれらのクエリとミューテーションを定義しています。
const typeDefs = gql`
type User {
id: ID!
name: String!
email: String!
}
type Post {
id: ID!
title: String!
author: User
}
type Query {
users: [User]
user(id: ID!): User
posts: [Post]
}
type Mutation {
addUser(name: String!, email: String!): User
}
`;サンプルデータ
サンプルデータとして、ユーザーと投稿のデータを含む配列を定義します。このデータは、リゾルバーによって返されます。
let users = [
{ id: '1', name: 'Alice', email: 'alice@example.com' },
{ id: '2', name: 'Bob', email: 'bob@example.com' },
];
let posts = [
{ id: '1', title: 'GraphQL Introduction', author: users[0] },
{ id: '2', title: 'GraphQL vs REST', author: users[1] },
];リゾルバー
リゾルバーは、クエリやミューテーションのリクエストに対してデータを返す関数です。例えば、usersクエリでは全ユーザーを返し、addUserミューテーションでは新しいユーザーを追加します。
const resolvers = {
Query: {
users: () => users,
user: (_, { id }) => users.find(user => user.id === id),
posts: () => posts,
},
Mutation: {
addUser: (_, { name, email }) => {
const newUser = { id: String(users.length + 1), name, email };
users.push(newUser);
return newUser;
},
},
};サーバーの起動
最後に、Apollo Serverを初期化し、サーバーを起動します。
const server = new ApolloServer({ typeDefs, resolvers });
server.listen().then(({ url }) => {
console.log(`Server ready at ${url}`);
});このコードを実行するには、ターミナルで以下のコマンドを実行します。
node index.js成功すると、以下のメッセージが表示されます。
Server ready at http://localhost:4000/この状態で、ブラウザを開き、http://localhost:4000/にアクセスすると、GraphQL Playgroundを使ってクエリを試すことができます。
まとめ
GraphQLは、柔軟で効率的なデータ取得方法を提供し、初心者にも理解しやすいAPI設計を可能にします。必要なデータだけを効率的に取得でき、開発の生産性が向上します。今回の記事で紹介した基本的なセットアップとクエリの実行を通じて、GraphQLの基本概念を理解し、簡単なアプリケーションを作成できるようになったと思います。
次に学ぶべきステップとして、以下のトピックについても学習を進めることをお勧めします。
-
GraphQLとデータベースの連携
- GraphQLサーバーとデータベース(例えば、MongoDBやPostgreSQL)を接続し、リゾルバーを通じてデータベース操作を行う方法。
-
リアルタイムデータのサブスクリプション
- GraphQLのサブスクリプション機能を使って、リアルタイムでデータの変更をクライアントに通知する方法。
-
認証と認可
- GraphQLサーバーでユーザー認証とアクセス制御を実装する方法。
-
GraphQLクライアントの利用
- Apollo ClientなどのGraphQLクライアントを使って、フロントエンドアプリケーションからGraphQLサーバーにクエリを送信する方法。
参考資料や公式ドキュメントを活用して、さらにGraphQLの理解を深めてください。
【番外編】USBも知らなかった私が独学でプログラミングを勉強してGAFAに入社するまでの話

プログラミング塾に半年通えば、一人前になれると思っているあなた。それ、勘違いですよ。「なぜ間違いなの?」「正しい勉強法とは何なの?」ITを学び始める全ての人に知って欲しい。そう思って書きました。是非読んでみてください。
「フリーランスエンジニア」
近年やっと世間に浸透した言葉だ。ひと昔まえ、終身雇用は当たり前で、大企業に就職することは一種のステータスだった。しかし、そんな時代も終わり「優秀な人材は転職する」ことが当たり前の時代となる。フリーランスエンジニアに高価値が付く現在、ネットを見ると「未経験でも年収400万以上」などと書いてある。これに釣られて、多くの人がフリーランスになろうとITの世界に入ってきている。私もその中の1人だ。数年前、USBも知らない状態からITの世界に没入し、そこから約2年間、毎日勉学を行なった。他人の何十倍も努力した。そして、企業研修やIT塾で数多くの受講生の指導経験も得た。そこで私は、伸びるエンジニアとそうでないエンジニアをたくさん見てきた。そして、稼げるエンジニア、稼げないエンジニアを見てきた。
「成功する人とそうでない人の違いは何か?」
私が出した答えは、「量産型エンジニアか否か」である。今のエンジニア市場には、量産型エンジニアが溢れている!!ここでの量産型エンジニアの定義は以下の通りである。
比較的簡単に学習可能なWebフレームワーク(WordPress, Rails)やPython等の知識はあるが、ITの基本概念を理解していないため、単調な作業しかこなすことができないエンジニアのこと。
多くの人がフリーランスエンジニアを目指す時代に中途半端な知識や技術力でこの世界に飛び込むと返って過酷な労働条件で働くことになる。そこで、エンジニアを目指すあなたがどう学習していくべきかを私の経験を交えて書こうと思った。続きはこちらから、、、、

エンベーダー編集部
エンベーダーは、ITスクールRareTECHのインフラ学習教材として誕生しました。 「遊びながらインフラエンジニアへ」をコンセプトに、インフラへの学習ハードルを下げるツールとして運営されています。


関連記事

2026.04.05
Python printの使い方|基本から出力方法まで初心者向けに解説
Pythonのprint関数の使い方を初心者向けに解説。基本の出力方法からf-string、引数のカスタマイズ、ファイル出力までを紹介。コード例と一緒に試してみる→
- プログラミング
- Python

2026.02.13
Cursorの導入方法|インストールと日本語化・AI機能の使い方を解説
CursorとはAI搭載のコードエディタです。インストール方法から日本語化の手順、AIによるコード生成・補完機能の使い方まで、初心者向けにわかりやすく解説します。
- プログラミング
- AI

2023.08.19
プログラミング学習って独学できる?結論から言うと可能、ただし
今回はエンジニア初学者の方に向けて「プログラミング学習を独学でする方法」を解説します。他にも「学習の流れ」や「独学で必要なスキル」「スクールとの比較」も紹介しているので、ぜひ参考にしてくださいね。
- プログラミング
- キャリア・学習法

2026.01.15
静的サイトと動的サイトの違い|目的と仕組みを比較表で解説
ウェブサイトには主に「静的サイト」と「動的サイト」の2つの大きなカテゴリがあります。それぞれの特性や用途を理解し、適切な場面での利用することが、ウェブサイトを成功させる鍵となります。
- プログラミング