オブジェクト関係マッピング(ORM:Object-Relational Mapping)とは、オブジェクト指向プログラミング言語とデータベースを結びつけるための技術です。関係データベース(RDB)のデータをオブジェクトとしてプログラムから直感的に扱えるようにし、データベース操作に関する処理の記述の煩雑さを軽減してより柔軟にアプリケーションを構築することを可能にします。ORMが登場した背景は、オブジェクト指向と関係データベースの考え方の違い(インピーダンス・ミスマッチ)を解消するためでした。
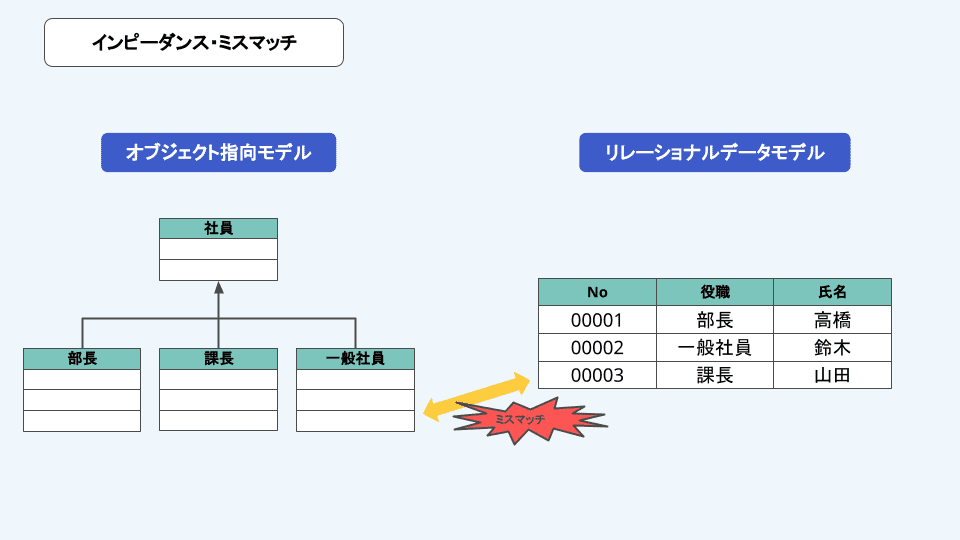
インピーダンス・ミスマッチとは
オブジェクト指向は現実世界の物事に即してデータモデルを定義している一方で、関係データベースはCRUD処理などデータベース操作に最適化してデータモデルを定義しています。これらの設計方針を混在させてしまうと、無理な表結合や複数テーブルにまたがる更新処理が多く発生してパフォーマンスが悪化するなどの不都合を招きます。
このようなデータモデルの設計思想の違いから生じる問題を「インピーダンス・ミスマッチ」と呼びます。

ORM以前の問題
ORMは名前の通り、「オブジェクト」と「関係データベース」をマッピング=対応付けするフレームワークと言えます。ORMフレームワークがない場合、マッピングをプログラマー自身が行わなければなりません。インピーダンス・ミスマッチが生じる「オブジェクト」と「関係データベース」をマッピングするコードを記述する作業は、非常に煩雑でありながら単調なコードの繰り返しである場合が多く気づきにくいバグが生じる危険性があります。
また、非オブジェクト指向言語であるSQLを意識しながらオブジェクト指向プログラムを書くことで、オブジェクト指向の柔軟性が損なわれる問題もあります。さらに、オブジェクトからデータを取り出してSQLに構築し直す作業も煩雑です。カラムに変更が生じた場合は、再びRDBにアクセスしてコードを修正する必要があります。
さらに、開発・運用の最中にRDBを移行することになればRDBMSの製品によるSQL文法の違いを一つ一つ確認・修正しなければなりません。
ORMのメリット
こうした問題を解決するために、ORMフレームワークが開発されました。ORMを使用することで、RDBにアクセスするプログラムをスマートに記述することができます。プログラマーはSQLを意識せずにデータを扱うことができ、ORMフレームワークがマッピング作業を行ってくれます。これにより、プログラマーはより柔軟で効率的なプログラミングを行うことができます。
またORMを使用するとSQLを直接記述せずにプログラミング言語でRDBを操作するコードを記述します。つまりRDBMSによるSQL文法の違いを吸収できるため、どのRDBMSでも同じように動作する点もORMのメリットと言えるでしょう。
ORMによるマッピング処理について
ORMによるマッピング処理は以下の流れで行われます。
- あらかじめ、クラスの属性とテーブルカラムの対応付け(Mapping)をXMLファイルなどの外部ファイルで定義する
- ORMフレームワークが外部ファイルで定義したクラスの属性とテーブルカラムのマッピングを処理する
- ORMフレームワークによって生成されたクラスを用いて、フレームワークの提供するAPIを用いてデータの保存や検索などの処理を記述する
ORMライブラリを利用したユースケース
プログラミング言語にはいくつかのORMライブラリが提供されています。中には各プログラミング言語のフレームワークに搭載されているものもあります。以下はORMライブラリの一例です。
| ORM | 言語 | webフレームワーク |
|---|---|---|
| SQLAlchemy | Python | |
| DjangoORM | Python | Django |
| Idiorm | PHP | |
| Eloquent | PHP | Laravel |
| ActiveRecord | Ruby | Ruby on Rails |
| TypeORM | TypeScript | |
| JavaScript | ||
| Sequelize | Node.js |
SQLAlchemy
SQLAlchemyはPythonプログラムのためのORMで最もメジャーなライブラリです。SQLAlchemyには以下のような代表的な機能があります。
- データベースへの接続、SQLクエリの実行
- メタデータ
- ORM
特にメタデータはSQLAlchemyの中でも強力な機能で、Pythonコードとテーブルを完全に同期させることが可能です。テーブルの変更をコードに、コードの変更をテーブルに適用することができ、開発中のマイグレーションの手間を省力化することができます。
またSQLAlchemyがサポートするRDBMSには以下が挙げられます。
- Microsoft SQL Server
- MySQL / MariaDB
- Oracle
- PostgreSQL
- SQLite
SQLAlchemyの操作例
SQLAlchemyを用いて、生徒を管理するstudentsテーブルを作成し、これがStudentsクラスと対応付けられている場合の操作例を以下に示します。こちらの例ではSQLiteを使用します。 ※詳しい記述方法・ルールは省略します。(参考:公式ドキュメント)
- データベースとの接続を確立、モデルを定義してテーブルを作成する
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# データベースに接続するためのエンジンを作成
engine = create_engine('sqlite:/// students.db', echo=True)
Base = declarative_base()
# Studentsクラスを定義
class Students(Base):
__tablename__ = 'students'
id = Column(Integer, primary_key=True)
name = Column(String)
club = Column(String)
# テーブルを作成する
Base.metadata.create_all(engine)
# データベースに接続・操作を行うためのセッションを作成する
Session = sessionmaker(bind=engine)
session = Session()- データを取得・表示する
# id = 1 のレコードを取得する
student = session.query(Students).filter_by(id=1).first()
# 取得したレコードのnameを表示する
print(student.name) # Student1 name- データを更新する
# 取得したレコードのclubを変更する
student.club = "New Club"
session.commit()- データを追加する
# データを追加する
new_student = Students(name="Alice", club="テニス")
session.add(new_student)
session.commit()このように、SQLを用いずにpythonプログラムからデータベース操作を行うことができます。
まとめ
オブジェクト指向プログラミング言語にはいくつかのORMライブラリが存在します。ORMはシステム構築では欠かせないデータベース操作を直感的に記述することができ、テーブルとソースコードの同期管理やRDBMSによるSQL文法の差異吸収などマッピング処理以外の利点も機能として備わっています。
しかしORMだけでプログラムからデータベース操作ができてしまうためプログラマーがSQLを書く・学ぶ機会が減ることが懸念されます。SQLはRDBを扱うために最適な言語でありRDBアクセスを行うシステムを構築する上では必要不可欠です。双方を理解してORMを利用することで、より柔軟にシステムを構築できるでしょう。
【番外編】USBも知らなかった私が独学でプログラミングを勉強してGAFAに入社するまでの話

プログラミング塾に半年通えば、一人前になれると思っているあなた。それ、勘違いですよ。「なぜ間違いなの?」「正しい勉強法とは何なの?」ITを学び始める全ての人に知って欲しい。そう思って書きました。是非読んでみてください。
「フリーランスエンジニア」
近年やっと世間に浸透した言葉だ。ひと昔まえ、終身雇用は当たり前で、大企業に就職することは一種のステータスだった。しかし、そんな時代も終わり「優秀な人材は転職する」ことが当たり前の時代となる。フリーランスエンジニアに高価値が付く現在、ネットを見ると「未経験でも年収400万以上」などと書いてある。これに釣られて、多くの人がフリーランスになろうとITの世界に入ってきている。私もその中の1人だ。数年前、USBも知らない状態からITの世界に没入し、そこから約2年間、毎日勉学を行なった。他人の何十倍も努力した。そして、企業研修やIT塾で数多くの受講生の指導経験も得た。そこで私は、伸びるエンジニアとそうでないエンジニアをたくさん見てきた。そして、稼げるエンジニア、稼げないエンジニアを見てきた。
「成功する人とそうでない人の違いは何か?」
私が出した答えは、「量産型エンジニアか否か」である。今のエンジニア市場には、量産型エンジニアが溢れている!!ここでの量産型エンジニアの定義は以下の通りである。
比較的簡単に学習可能なWebフレームワーク(WordPress, Rails)やPython等の知識はあるが、ITの基本概念を理解していないため、単調な作業しかこなすことができないエンジニアのこと。
多くの人がフリーランスエンジニアを目指す時代に中途半端な知識や技術力でこの世界に飛び込むと返って過酷な労働条件で働くことになる。そこで、エンジニアを目指すあなたがどう学習していくべきかを私の経験を交えて書こうと思った。続きはこちらから、、、、

エンベーダー編集部
エンベーダーは、ITスクールRareTECHのインフラ学習教材として誕生しました。 「遊びながらインフラエンジニアへ」をコンセプトに、インフラへの学習ハードルを下げるツールとして運営されています。


関連記事

2026.03.12
左結合(LEFT JOIN)と右結合の違い|SQL結合の使い方を解説
左結合(LEFT JOIN)とは、基準テーブルの全データを残しつつ結合する方法です。右結合(RIGHT JOIN)との違いや使い分け、具体的なSQL文の書き方を例を交えて解説します。
- データベース
2023.03.18
【DB】クライアントツール「Table Plus」の導入方法と基本操作を解説
TablePlusは**GUI**でデータベースを操作することのできるクライアントツールです。
- データベース

2023.08.27
エンジニア初学者向け RDBの概念と歴史の理解
本記事はRDBの基礎やその歴史的背景を簡単に紹介し、この分野の魅力や重要性を伝えることを目的とします。
- データベース
2025.12.10
【DB】初心者向けクライアントツール「DBeaver」の導入方法
DBeaverはデータベースをGUIで操作できる管理ツール。インストールから日本語化、接続までを図解で理解。今日からDB操作を簡単に管理できます。
- データベース