クラウド環境における監視の重要性と課題
クラウド環境は、物理的な制約から解放された柔軟性と拡張性を備えますが、その複雑性から、システムの状態をリアルタイムで把握し、効率的な運用を行うための継続的な監視が不可欠です。予期せぬトラフィックの急増やリソース不足といった課題に対し、迅速な対応が求められます。
AWS CloudWatchとは?
AWS CloudWatchは、AWS上で稼働するシステムの健全性を維持するための包括的なモニタリングサービスです。メトリクス(測定可能なデータポイント)収集、アラーム設定、ログ管理・分析、ダッシュボード作成など、多様な機能を提供し、クラウド環境における監視の羅針盤として機能します。今回はそのうち、システム運用において必須であろうアラームについて解説していきます。
CloudWatchアラームの設定と重要性
AWS CloudWatchのアラーム機能は、AWSリソースの監視において中心的な役割を果たします。アラームを利用することで、特定のメトリクスが設定されたしきい値を超えた際に自動的に通知を受け取り、迅速に対応することが可能になります。ここでは、アラームの設定方法と、運用におけるその重要性について詳しく解説します。
アラーム設定のステップ
-
メトリクスの選定
監視するAWSサービスとリソースを選択し、関連するメトリクスを特定します。
-
しきい値の設定
メトリクスに対するしきい値を定義します。このしきい値は、通常の運用範囲を超えた場合にアラームを発生させる基準となります。
-
通知の設定
アラームがトリガーされた際に誰が通知を受けるかを設定します。これには、EメールアドレスやSMS、AWS SNSトピックなどが利用されます。
CloudWatchで実現する包括的なモニタリング
次章では、CloudWatchで特に注意すべき監視項目とその設定方法について詳しく解説します。具体的には、以下の内容を網羅します。
-
サーバ監視
- CPU使用率
- メモリ使用量
- ディスク使用量
- ネットワークトラフィック
- エラーログ
-
アプリケーション監視
- HTTPステータスコード
- リクエスト時間
- データベース接続数
- アプリケーションログ
-
インフラストラクチャ監視
- EC2インスタンスの状態
- EBSボリュームの状態
- S3ストレージの使用量
- ELBのヘルスチェック
-
セキュリティ監視
- ログイン失敗
- セキュリティグループの変更
- IAMロールのアクセス
- VPCフローログ
これらの監視項目を設定することで、システムの健全性を維持し、問題発生時の迅速な対応を実現できます。
アプリケーション監視
アプリケーションの健全性とパフォーマンスを維持するためには、適切な監視が不可欠です。CloudWatchを活用することで、アプリケーションの状態をリアルタイムに把握し、問題発生時の迅速な対応を実現できます。
主要な監視項目
以下の主要な監視項目に注目することで、アプリケーションの健全性とパフォーマンスを効果的に管理できます。
1. HTTPステータスコード
- 200系統: 正常なリクエストを示します。
- 400系統: クライアントエラーを示します。
- 500系統: サーバーエラーを示します。
200系を除くこれらのコードの増加は、問題発生の兆候となります。異常コードの比率を監視し、迅速な対応策を講じましょう。
2. リクエスト時間:パフォーマンス低下を察知
- リクエスト応答時間の増加は、アプリケーションのパフォーマンス低下を示します。
- サーバーの負荷増大、リソース不足、バックエンドの問題が原因となる可能性があります。
リクエスト時間指標を監視し、スケーリングの必要性やリソースの調整を判断しましょう。
3. データベース接続数:負荷とスケーリングの判断
- データベースへの同時接続数の急増は、パフォーマンス低下やタイムアウト増加につながる可能性があります。
- この指標を監視することで、スケーリングの必要性を判断し、リソースの調整を行うことができます。
4. アプリケーションログ:詳細な情報で原因を特定
- エラーログや警告ログは、アプリケーション内部で発生している問題を詳細に記録します。
- ログ分析を通じて、エラーの原因を特定し、再発防止策を講じることが可能です。
トラフィック増加時の監視例
事例
あるEC商用サイトでは、大規模なセールイベント中にトラフィックが通常の5倍に増加しました。
課題
- システムへの負荷増大
- パフォーマンス低下
- エラー発生
CloudWatchによる迅速な対応
- 事前の監視設定
- イベント前に、HTTPステータスコード、リクエスト時間、データベース接続数を継続的に監視するためのアラームを設定
- 問題の発生
- イベント開始後、500系統のエラーコードが増加
- リクエスト時間も通常の2倍に達し、データベース接続数が急激に増加していることを確認
- 迅速な対応
- CloudWatchのアラームによって、システム管理者は即座に通知を受け、迅速にトラフィック分散のための追加インスタンスをデプロイ
- データベースのリソースも増強し、パフォーマンスの低下を解消
結果
- トラフィック増加に対応し、システムの安定稼働を維持しました。
- ダウンタイムや顧客満足度の低下を防ぎました。
CloudWatchを活用することで、このような突発的な状況にも迅速に対応し、アプリケーションの健全性とパフォーマンスを維持することができます。
インフラストラクチャ監視
インフラストラクチャの健全性を確認するためには、以下の重要な監視項目に注目する必要があります。これらの項目を通じて、AWSリソースのパフォーマンスと安定性を効率的に管理し、問題発生時に迅速に対応できる体制を整えることが重要です。
主要な監視項目
-
EC2インスタンスの状態
- メトリクス
StatusCheckFailed_Instance- 監視対象
EC2インスタンスがシステムチェックとインスタンスチェックの両方で問題がないかどうか。
- アラーム設定
システムステータスチェックやインスタンスステータスチェックで失敗があった場合にアラームを設定。
-
推奨アラーム設定
- しきい値
ステータスチェックが1以上(任意の問題がある場合)
- 期間
5分間
- アクション
このアラームがトリガーされると、関連するシステム管理者に通知し、オートスケーリングを使って新しいインスタンスを起動します。
-
EBSボリュームの状態
- メトリクス
VolumeStatusCheckFailed- 監視対象
EBSボリュームの健全性とパフォーマンス。
- アラーム設定
ボリュームのステータスチェックが警告または異常を示した場合にアラームを設定。
-
推奨アラーム設定
- しきい値
チェック失敗が1回以上
- 期間
1時間
- アクション
エラー通知を送信し、データバックアッププロセスを開始します。
-
S3ストレージの使用量
- メトリクス
BucketSizeBytes,NumberOfObjects- 監視対象
S3バケットの総容量とオブジェクト数。
- アラーム設定
データ使用量が一定のしきい値を超えた場合、または急激な増加が見られる場合にアラームを設定。
-
推奨アラーム設定
- しきい値
使用量が設定された容量の80%を超えた場合
- 期間
24時間
- アクション
ストレージの最適化またはクリーンアッププロセスをトリガーします。
-
ELBのヘルスチェック
- メトリクス
UnHealthyHostCount- 監視対象
Elastic Load Balancer (ELB) に接続されているヘルスチェックに合格していないホストの数。
- アラーム設定
ヘルスチェックに失敗するインスタンスの数が一定数を超えた場合にアラームを設定。
-
推奨アラーム設定
- しきい値
1以上のヘルスチェック失敗
- 期間
10分間
- アクション
自動的に問題のあるインスタンスを置き換えます。
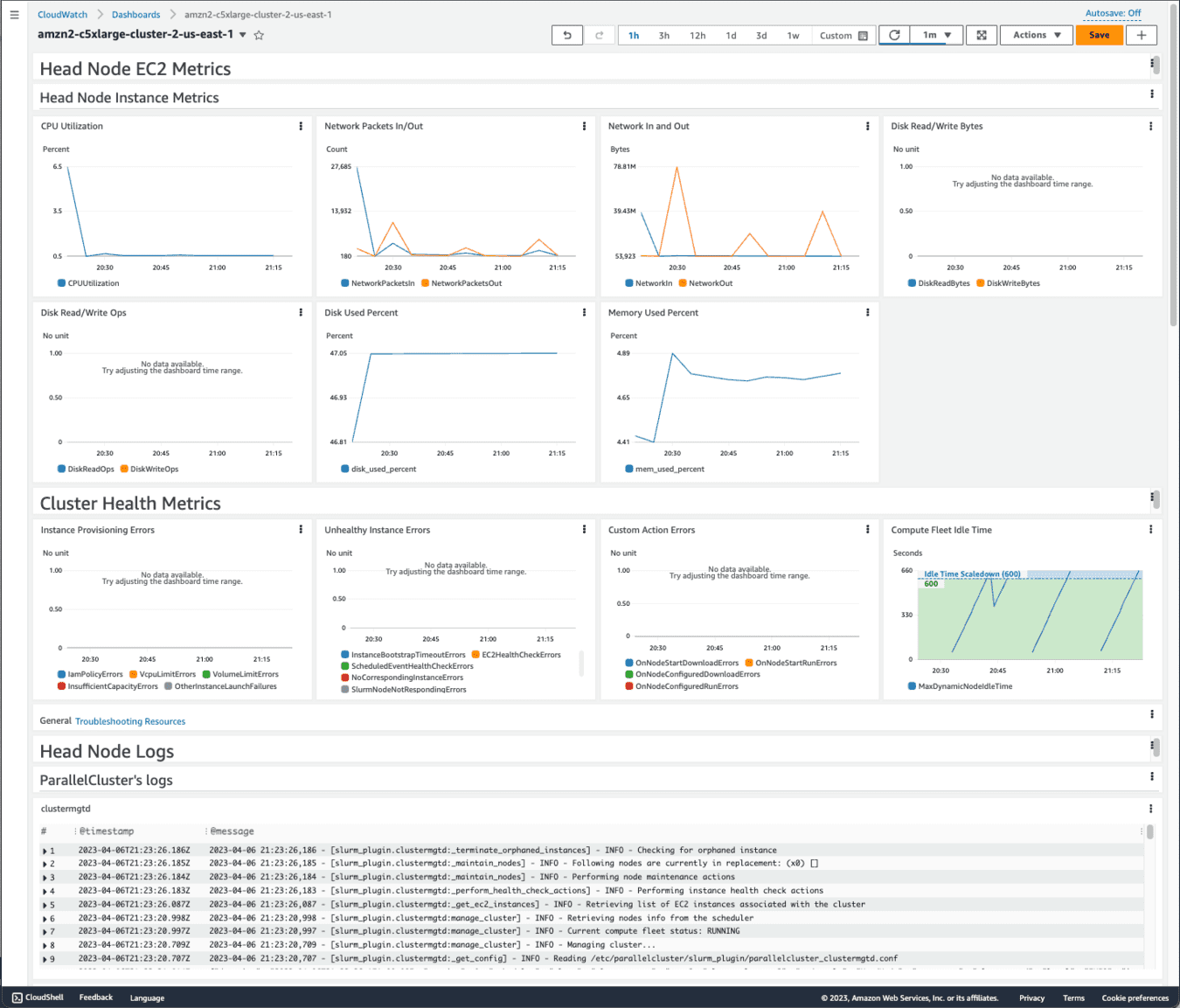
ダッシュボードで可視化し、迅速な意思決定
 CloudWatchダッシュボードの画面イメージ(引用元URL: https://docs.aws.amazon.com/ja_jp/parallelcluster/latest/ug/cloudwatch-dashboard-v3.html)
CloudWatchダッシュボードの画面イメージ(引用元URL: https://docs.aws.amazon.com/ja_jp/parallelcluster/latest/ug/cloudwatch-dashboard-v3.html)
CloudWatchダッシュボードは、AWSリソースの監視と管理を効率化するツールです。適切に構成することで、システム全体の状況をリアルタイムに可視化し、問題発生時の迅速な意思決定を可能にします。
ダッシュボード構成のポイント
-
セクションの整理で論理的なグループ分け
- リソース別セクション
EC2、EBS、S3、ELBなど、リソース種別ごとにセクションを分けます。関連するメトリクスを一括表示することで、問題の迅速な特定と対応が可能になります。
- 機能別セクション
パフォーマンス、可用性、セキュリティなどの機能ごとにグループ化します。特定の監視目的に特化した情報へ迅速にアクセスできます。
-
適切なメトリクス選択で重要な指標を明確に
各セクションには、そのリソースに最も関連性の高いメトリクスを選択して表示します。 例:EC2セクションでは
CPUUtilization,StatusCheckFailed,NetworkIn/Out、EBSではVolumeReadBytes,VolumeWriteBytes,VolumeIdleTimeなどを選択します。 -
リアルタイムデータ可視化でグラフとゲージで状況を把握
グラフとゲージを利用して、各メトリクスのリアルタイムデータを視覚的に表現します。グラフは時間経過によるデータの変動を捉え、ゲージはリアルタイムの状態を即座に把握するのに役立ちます。グラフの時間範囲をカスタマイズすることで、直近のデータだけでなく、過去のトレンドを分析することも可能です。
-
アラート統合で迅速な対応を可能に
ダッシュボードには、設定したアラームのステータスも表示します。アラームがトリガーされた際に、どのメトリクスが原因であるかを即座に特定し、適切な対応を取ることができます。
ダッシュボードの利用効果でメリットを最大限に
-
効率的なトラブルシューティングにより問題解決を迅速化
問題発生時に、関連するメトリクスやリソースを迅速に確認することで、問題の原因を特定し、解決策を迅速に実行できます。
-
システム全体の可視化し全体像を把握
すべての重要なリソースとメトリクスを一つの画面で確認できるため、システム全体の健康状態を一目で理解できます。
-
迅速な意思決定が可能
可視化された情報に基づいて、迅速かつ的確な意思決定を行うことができます。
CloudWatchダッシュボードは、AWS環境の監視と管理を効率化し、システム全体の安定稼働を実現するための必須ツールです。
セキュリティ監視の概要
セキュリティの監視は、AWS環境内の潜在的な脅威と異常を検出し、適切な対応を迅速に行うために不可欠です。
監視項目とアラーム設定
-
ログイン失敗(
ConsoleLoginFailures)- 監視対象
AWS管理コンソールへの失敗したログイン試行。
- アラーム設定
短時間に多数の失敗が発生した場合に通知。
-
セキュリティグループの変更(
SecurityGroupChanges)- 監視対象
セキュリティグループ設定の変更。
- アラーム設定
変更があった際に即時通知。
-
IAMロールのアクセス(
IAMPolicyChanges)- 監視対象
IAMポリシーの変更と異常なアクセス試み。
- アラーム設定
不正アクセスやポリシー変更時に警告。
-
VPCフローログ(
RejectedConnectionCount)- 監視対象
VPC内の拒否された接続試行。
- アラーム設定
拒否された接続の急増を検出した場合にアラート。
トラブルシューティングのガイド
- アラーム発動時の一般的な対応
-
即時確認
アラームの詳細を確認し、関連するログや設定を速やかにレビュー。
-
原因特定と対応
問題の原因を特定した後、必要に応じてアクセス制限の強化や設定の復旧を行う。
-
ドキュメント更新と報告
事件の詳細を記録し、セキュリティポリシーを更新することで再発防止に努める。
-
監視のベストプラクティス
クラウド環境での監視は、システムの健全性、セキュリティ、およびパフォーマンスを維持するための基本的な要素です。効果的な監視を行うためには、以下のベストプラクティスを実践することが重要です。
効果的な監視のためのヒント
-
適切なメトリクスの選定
システムの重要な側面を反映するメトリクスを選び、必要な情報を常に手元に保つことが重要です。
-
しきい値の設定
メトリクスごとに適切なしきい値を設定し、異常な振る舞いや問題を早期に検出できるようにします。
-
通知のカスタマイズ
重要度に応じてアラートの優先順位を設定し、必要なステークホルダーに適切なタイミングで情報が届くようにします。
-
定期的なレビューと調整
監視プロセスは定期的にレビューし、新しい要件や変更された条件に応じて調整を行います。
-
継続的な学習と改善
監視ツールや技術の進化に常に注意を払い、システム監視の効果を最大限に高めるための新しい方法を取り入れます。
参考リンク
【番外編】USBも知らなかった私が独学でプログラミングを勉強してGAFAに入社するまでの話

プログラミング塾に半年通えば、一人前になれると思っているあなた。それ、勘違いですよ。「なぜ間違いなの?」「正しい勉強法とは何なの?」ITを学び始める全ての人に知って欲しい。そう思って書きました。是非読んでみてください。
「フリーランスエンジニア」
近年やっと世間に浸透した言葉だ。ひと昔まえ、終身雇用は当たり前で、大企業に就職することは一種のステータスだった。しかし、そんな時代も終わり「優秀な人材は転職する」ことが当たり前の時代となる。フリーランスエンジニアに高価値が付く現在、ネットを見ると「未経験でも年収400万以上」などと書いてある。これに釣られて、多くの人がフリーランスになろうとITの世界に入ってきている。私もその中の1人だ。数年前、USBも知らない状態からITの世界に没入し、そこから約2年間、毎日勉学を行なった。他人の何十倍も努力した。そして、企業研修やIT塾で数多くの受講生の指導経験も得た。そこで私は、伸びるエンジニアとそうでないエンジニアをたくさん見てきた。そして、稼げるエンジニア、稼げないエンジニアを見てきた。
「成功する人とそうでない人の違いは何か?」
私が出した答えは、「量産型エンジニアか否か」である。今のエンジニア市場には、量産型エンジニアが溢れている!!ここでの量産型エンジニアの定義は以下の通りである。
比較的簡単に学習可能なWebフレームワーク(WordPress, Rails)やPython等の知識はあるが、ITの基本概念を理解していないため、単調な作業しかこなすことができないエンジニアのこと。
多くの人がフリーランスエンジニアを目指す時代に中途半端な知識や技術力でこの世界に飛び込むと返って過酷な労働条件で働くことになる。そこで、エンジニアを目指すあなたがどう学習していくべきかを私の経験を交えて書こうと思った。続きはこちらから、、、、

エンベーダー編集部
エンベーダーは、ITスクールRareTECHのインフラ学習教材として誕生しました。 「遊びながらインフラエンジニアへ」をコンセプトに、インフラへの学習ハードルを下げるツールとして運営されています。


関連記事

2024.09.30
【Terraformハンズオン】LambdaとGatewayエンドポイントを使ってS3にファイルを配置しよう
この記事では、Gatewayエンドポイントについて解説し、Terraformを使用してプライベートサブネットにあるLambda関数から、S3バケットにファイルをアップロードするハンズオンを行います。
- Terraform
- AWS

2024.01.28
Undifferentiated Heavy Liftingとは?重労働から解放されるクラウド時代の新戦略
クラウドコンピューティングの文脈でよく使われるこの用語は、企業や開発者が自社のコアビジネスやイノベーションに集中する代わりに、基本的でありながら重要なインフラストラクチャやシステム管理などの作業に多くの時間とリソースを費やしている状況を指します。
- AWS
- インフラエンジニア

2024.10.31
aws_iam_policy_attachmentは使わない方がいい?誤ったポリシー管理で起きるリスクと対策
この記事では、aws_iam_policy_attachmentの概要と一般的な利用ケースについて紹介し、その利便性と潜在的なリスクについて理解を深めます。
- AWS
2025.12.10
AWSのリージョンとAZ(アベイラビリティゾーン)の違いと役割を解説
AWSのAZは同じリージョン内にある独立データセンターのこと。AZとリージョンの違いや役割を整理すれば、AWS構成に自信を持てるようになります。
- AWS